
ماشین لرنینگ چیست؟
راهنمای جامع مبانی و کاربردهای ماشین لرنینگ
- ماشین لرنینگ (یادگیری ماشینی) چیست؟
- انواع یادگیری ماشینی
- تفاوت بین هوش مصنوعی و یادگیری ماشینی چیست؟
- هوش مصنوعی چیست؟
- سه نوع هوش مصنوعی
- یادگیری ماشینی چیست؟
- هوش مصنوعی و ML چگونه به هم مرتبط هستند؟
- هوش مصنوعی نمادین
- کاربردهای ML: رگرسیون
- رگرسیون خطی
- روشهای رگرسیون غیرخطی
- پیش بینی احتمالات با رگرسیون لجستیک
- کاربردهای ML: طبقه بندی
- K-Nearest Neighbours (KNN)
- ماشینهای بردار پشتیبانی (SVM)
- طبقه بندی کننده های نرم در مقابل سخت
- طبقه بندی کننده های غیر خطی SVM
- درختان طبقه بندی
- یادگیری عمیق (Deep Learning)
- چرا شبکه های عصبی عمیق هستند؟
- با این حال، این سوال پیش میآید که چرا شبکههای عصبی باید عمیق باشند؟
- منابع داده آموزش یادگیری ماشین
- داده های ساختاریافته در مقابل داده های بدون ساختار
- فرمت های داده های ساختاریافته در مقابل غیرساختار
- منابع داده های ساخت یافته
- منابع داده بدون ساختار
- تجزیه و تحلیل داده های ساخت یافته
- چگونه بفهمیم که داده های شما کمی هستند یا دسته بندی
- نمونه هایی از مدل های هوش مصنوعی که می توانید با داده های کمی بسازید
- چه چیزی بهتر است: داده های کمی یا طبقه ای؟
- چه چیزی رایج تر است: داده های کمی یا طبقه ای؟
- مهندسی ویژگی برای داده های سری زمانی
- مدل های ML در هر اندازه ای
- کمیت همه چیز نیست
- آزمایش کنید تا متوجه شوید به چه مقدار داده نیاز دارید
- آماده سازی داده ها برای یادگیری ماشینی
- افزایش داده برای یادگیری ماشین
- تعصب در یادگیری ماشینی: چیست و چگونه می توان از آن اجتناب کرد؟
- از موارد یادگیری ماشین استفاده کنید
- انرژی
- بیمه
- مدل سازی توسعه دعوی
- مدلسازی اتوماسیون پرداخت دعوی
- مدل سازی تبدیل بیمه
- مدل سازی ادعای تقلبی (Fraudulent Claim Modeling )
- پذیرش کردن بیمه عمر برای مشتریان ضعیف
- فین تک و بانکداری
- مراقبت های بهداشتی
- بخش عمومی
- پشتیبانی مشتری
- بازاریابی
- چگونه می توانم یک مدل یادگیری ماشین ایجاد و اجرا کنم؟
ماشین لرنینگ (یادگیری ماشینی) چیست؟
ماشین لرنینگ شاخهای از علوم کامپیوتر است که به رایانهها اجازه میدهد به طور خودکار الگوها را از دادهها استنتاج کنند بدون اینکه به صراحت گفته شود که این الگوها چیست. این استنتاج ها اغلب مبتنی بر استفاده از الگوریتم هایی برای بررسی خودکار ویژگی های آماری داده ها و ایجاد مدل های ریاضی برای نشان دادن رابطه بین کمیت های مختلف است.
بیایید این را با محاسبات سنتی مقایسه کنیم، که بر سیستمهای قطعی تکیه میکند، که در آن به صراحت مجموعهای از قوانین را برای انجام یک کار خاص به رایانه میگوییم. این روش برنامه نویسی کامپیوترها را مبتنی بر قوانین می نامند. در جایی که یادگیری ماشین با آن تفاوت دارد و جایگزین آن می شود، برنامه نویسی مبتنی بر قوانین این است که به تنهایی قادر به استنباط این قوانین است.
فرض کنید که یک مدیر بانک هستید و میخواهید بفهمید که آیا متقاضی وام احتمالاً وام خود را نکول میکند یا خیر. در یک رویکرد مبتنی بر قوانین، مدیر بانک (یا سایر کارشناسان) به صراحت به رایانه میگویند که اگر امتیاز اعتباری متقاضی کمتر از یک آستانه باشد، درخواست را رد کنید.
با این حال، یک الگوریتم یادگیری ماشینی به سادگی دادههای تاریخی مربوط به امتیازات اعتباری مشتریان و نتایج وام آنها را دریافت میکند و به خودی خود تعیین میکند که این آستانه چقدر باید باشد. با انجام این کار، دستگاه از دادههای تاریخی یاد میگیرد و قوانین خود را ایجاد میکند.
البته این فقط مقدمهای برای یادگیری ماشینی است، زیرا مدلهای یادگیری ماشین در دنیای واقعی معمولاً بسیار پیچیدهتر از یک آستانه ساده هستند. با این حال، این یک مثال عالی از قدرت یادگیری ماشینی است.
هر KPI سازمانی را می توان تا زمانی که داده های مربوطه را در اختیار داشت، بهینه کرد. برای مثال، با توجه به مجموعه دادههای مشتری تاریخی، میتوانید پیشبینی کنید که کدام یک از مشتریان فعلی شما در خطر ترک هستند، بنابراین میتوانید قبل از وقوع آن، این را متوقف کنید.
رویکردهای مدرن برای یادگیری ماشینی پیشرفت های بزرگی داشته اند و می توانند خیلی بیشتر از این کار را انجام دهند. الگوریتمهای یادگیری ماشینی، از ماشینهای خودران گرفته تا تشخیص صدا گرفته تا سیستمهای فیلتر خودکار ایمیلها که هرزنامهها را در صندوق ورودی شما علامتگذاری میکنند، اساس بسیاری از پیشرفتهای فناوری را تشکیل میدهند که امروزه به آن وابسته شدهایم.
در مرحله بعد، بیایید انواع مختلف الگوریتم های یادگیری ماشین و انواع خاصی از مسائل را که می توانند حل کنند، در نظر بگیریم.
انواع یادگیری ماشینی
الگوریتمهای یادگیری ماشین اغلب به سه دسته کلی تقسیم میشوند (اگرچه از طرحهای طبقهبندی دیگر نیز استفاده میشود): یادگیری تحت نظارت، یادگیری بدون نظارت و یادگیری تقویتی.

یادگیری تحت نظارت
یادگیری ماشینی نظارت شده به کلاسهایی از الگوریتمها اشاره دارد که در آن مدل یادگیری ماشین مجموعهای از دادهها با برچسبهای صریح برای کمیتی که به آن علاقهمندیم داده میشود (این کمیت اغلب به عنوان پاسخ یا هدف نامیده میشود).
یادگیری نیمه نظارت شده از ترکیبی از داده های برچسب دار و بدون برچسب برای آموزش مدل های هوش مصنوعی استفاده می کند.
اگر با داده های بدون برچسب سر و کار دارید، باید برچسب گذاری داده ها را انجام دهید. برچسبگذاری فرآیند حاشیهنویسی مثالهایی برای کمک به آموزش یک مدل یادگیری ماشینی است. برچسب زدن معمولا توسط انسان انجام می شود که می تواند گران و زمان بر باشد. با این حال، راههایی برای خودکار کردن فرآیند برچسبگذاری وجود دارد.
یک مثال عالی از یادگیری تحت نظارت، سناریوی درخواست وام است که قبلاً در نظر گرفتیم. در اینجا، ما دادههای تاریخی در مورد امتیازات اعتباری متقاضیان وام قبلی (و سطح درآمد احتمالی، سن و غیره) در کنار برچسبهای صریح داشتیم که به ما میگفتند آیا شخص مورد نظر در پرداخت وام خود نکول کرده است یا خیر.
الگوریتم های یادگیری تحت نظارت را می توان بیشتر به رگرسیون و طبقه بندی تقسیم کرد. این تفاوت به نوع کمیت مورد نظر ما اشاره دارد.
اگر هدف انتخابی بین چند دسته مجزا باشد – برای مثال، آیا متقاضی پیشفرض میشود یا نه، آیا این تصویر یک گربه، یک سگ، یا یک انسان و غیره است – آنگاه مشکل به عنوان طبقهبندی نامیده میشود. ما در حال تلاش برای تعیین کلاسی هستیم که یک نقطه داده معین به آن تعلق دارد.
با این حال، اگر متغیر هدف ما پیوسته باشد، مشکل به عنوان رگرسیون نامیده میشود. به عنوان مثال، پیش بینی قیمت یک خانه با توجه به تعداد اتاق خواب ها و موقعیت آن.
یادگیری بدون نظارت
در مسائل یادگیری بدون نظارت، دادههایی که به ما داده میشود فاقد برچسب هستند و ما صرفاً به دنبال الگوها هستیم. مثلاً بگویید آمازون هستید. با توجه به سابقه خرید مشتریان، آیا میتوانیم خوشههایی (گروههایی از مشتریان مشابه) را شناسایی کنیم؟
در این سناریو، حتی اگر دادههای صریح و قطعی در مورد علایق یک فرد نداریم، فقط شناسایی اینکه گروه خاصی از مشتریان اقلام مشابهی را خریداری میکنند میتواند به ما اجازه دهد تا توصیههای خرید را بر اساس آنچه دیگر افراد در خوشه نیز دارند ارائه دهیم. خریداری شده است. سیستمهای مشابه همان چیزی است که به چرخ فلک آمازون «شما هم علاقهمند باشید» است.
خوشهبندی K-means نوعی مدل خوشهبندی است که گروههای مختلف مشتریان را میگیرد و بر اساس شباهتهای موجود در الگوهای رفتاری آنها را به خوشهها یا گروههای مختلف اختصاص میدهد. در سطح فنی، با یافتن مرکز برای هر خوشه کار می کند، که سپس به عنوان میانگین اولیه برای خوشه استفاده می شود. سپس مشتریان جدید بر اساس شباهت آنها به دیگر اعضای آن خوشه به خوشه ها اختصاص داده می شوند.

علاوه بر این، هنگامی که خوشه ها را شناسایی کردیم، می توانیم ویژگی های آنها را مطالعه کنیم. به عنوان مثال، فرض کنید می بینیم که یک خوشه معین در حال خرید بازی های ویدیویی زیادی است. در آن صورت، میتوانیم حدس بزنیم که این گروه از مشتریان گیمر هستند، حتی اگر هیچکس واقعاً به ما این را نگفته باشد.
هنگامی که این شکل از تجزیه و تحلیل را انجام دادیم، حتی میتوانیم از برچسبهای یادگیری بدون نظارت برای ایجاد مدلهای یادگیری نظارتشده استفاده کنیم که به عنوان مثال، ممکن است به ما امکان پیشبینی مقدار پولی را که یک گیمر 25 ساله با آن خرج میکند، میدهد.
یادگیری تقویتی
یادگیری تقویتی کلاسی از الگوریتمهای یادگیری ماشین است که در آن ما یک عامل رایانه را برای انجام برخی کارها بدون ارائه راهنمایی زیادی به او در مورد اینکه دقیقاً چه کاری انجام دهد، اختصاص میدهیم.
در عوض، رایانه مجاز است انتخابهای خود را انجام دهد و بسته به اینکه این انتخابها به نتیجهای که میخواهیم منجر شود یا نه، جریمهها و پاداشهایی را تعیین میکنیم. ما این فرآیند را چندین بار تکرار میکنیم و به رایانه اجازه میدهیم روش بهینه انجام کاری را با آزمون و خطا و تکرارهای مکرر بیاموزد.
به این به عنوان رویکرد هویج و چوب برای یادگیری ماشین فکر کنید. تقریباً مثل این است که رایانه در حال انجام یک بازی ویدیویی است و کشف می کند که چه چیزی کار می کند و چه چیزی کار نمی کند.
جالب اینجاست که بازی کردن دقیقاً کاربردی است که در آن یادگیری تقویتی شگفتانگیزترین نتایج را نشان داده است. مدل بدنام AlphaGo گوگل، که حتی بالاترین رتبهبندی بازیکنان انسانی Go را شکست داد، با استفاده از یادگیری تقویتی ساخته شد.
گوگل از آن زمان همان فناوری را به AlphaZero، جانشین AlphaGo اصلی که به عنوان مرجع توسط شطرنج بازان برای تعیین بهترین استراتژی ها استفاده می شود، گسترش داده است.
یادگیری عمیق
اگر یادگیری ماشینی را در اخبار دیده باشید، تقریباً مطمئناً در مورد یادگیری عمیق نیز شنیده اید. و ممکن است در این مرحله تعجب کنید که یادگیری عمیق در پارادایم فوق کجا قرار می گیرد.
و پاسخ همه آن ها است.
یادگیری عمیق زیرمجموعه ای از یادگیری ماشینی است که یک مشکل را به چندین “لایه” از “نورون ها” تقسیم می کند. این نورونها بر اساس نحوه عملکرد نورونها در مغز انسان بسیار ضعیف مدلسازی میشوند.
این کلاس از یادگیری ماشینی به عنوان یادگیری عمیق نامیده میشود، زیرا شبکه عصبی مصنوعی معمولی (مجموعه تمام لایههای نورونها) اغلب حاوی لایههای زیادی است.
در حالی که یادگیری عمیق در ابتدا برای مشکلات یادگیری تحت نظارت استفاده می شد، پیشرفت های اخیر قابلیت های آن را به مشکلات یادگیری بدون نظارت و تقویتی گسترش داده است.
و نتایج فوق العاده ای از خود نشان داده اند. بسیاری از آخرین پیشرفتها در بینایی کامپیوتر، که ماشینهای خودران و سیستمهای تشخیص چهره به آن وابسته هستند، ریشه در استفاده از مدلهای یادگیری عمیق دارند. پردازش زبان طبیعی، که به رایانهها اجازه میدهد مکالمات طبیعی انسان را درک کنند و سیری و دستیار گوگل را قدرتمند میکند، موفقیت خود را نیز مدیون یادگیری عمیق است.
رونق امروزی هوش مصنوعی عمدتاً به لطف پیشگامان یادگیری عمیق است: جفری هینتون، یان لیکان و یوشوا بنجیو. این مهندسان هوش مصنوعی به دلیل پیشرفت های چشمگیر خود در شبکه های عصبی عمیق، جایزه تورینگ را دریافت کردند.
تفاوت بین هوش مصنوعی و یادگیری ماشینی چیست؟
اگر تا به حال به وب سایت یک شرکت فناوری نگاه کرده باشید یا سخنرانی اصلی آخرین آیفون های اپل را تماشا کرده باشید، ممکن است عباراتی مانند هوش مصنوعی (AI) و یادگیری ماشین (ML) را دیده باشید که در همه جا ظاهر می شوند.
این کلمات اغلب به جای یکدیگر در نظر گرفته می شوند، اگرچه تفاوت های ظریف و مهمی بین آن ها وجود دارد. بنابراین، بیایید ببینیم که هر دوی این اصطلاحات دقیقاً چه معنایی دارند و چگونه همه آن ها با یکدیگر مرتبط هستند.
برای شروع، اجازه دهید ابتدا هر یک از این اصطلاحات را تعریف کنیم و سپس به این سوال که چگونه آن ها با هم مرتبط هستند، بپردازیم.
هوش مصنوعی چیست؟
در حالی که امکان نوشتن کتابی در زمینه هوش مصنوعی که علوم کامپیوتر، تاریخ، فلسفه و ماهیت هوش را پوشش می دهد، وجود دارد، اجازه دهید همه چیز را ساده نگه داریم. ساده ترین و در دسترس ترین راه برای تعریف هوش مصنوعی صرفاً نگاه کردن به کلمات است: این تلاشی برای ایجاد هوش است.
رشته هوش مصنوعی تئوری و عمل سیستم های هوشمند، به ویژه تصمیم گیری و یادگیری خودکار را مطالعه می کند.
به عبارت کمتر انتزاعی، این تلاشی است برای اجازه دادن به کامپیوترها برای تقلید از درک انسان از جهان و همچنین توانایی ما برای استدلال با آن.
البته این یک دستور بلند است، اما هدف نهایی تحقیقات هوش مصنوعی را به خوبی خلاصه می کند. ترمیناتور را در نظر بگیرید. این یک ماشین خیالی بود که کاملاً قادر بود جهان ما را هدایت کند، اطلاعات جدیدی را در مورد محیط اطراف خود و طبیعت بسیار پویای جهان و ساکنان آن ترکیب کند و بدون نیاز به هیچ دستورالعملی از سوی انسان تصمیمات مستقل بگیرد.
این تعریف همچنین کاملاً روشن می کند که ما با دستیابی به هوش مصنوعی واقعی فاصله بسیار زیادی داریم.
با این حال، سهم هوش مصنوعی امروزی تقریباً نامحدود است. مزایای هوش مصنوعی در حال حاضر در بسیاری از صنایع از جمله پزشکی، کشاورزی، تولید و یا صرفاً فروش و بازاریابی احساس می شود. هوش مصنوعی روش کار، بازی و تعامل ما با یکدیگر را تغییر میدهد، از ابزارهایی که استفاده میکنیم تا راههایی که با سازمانهایی که تشکیل میدهیم ارتباط برقرار میکنیم.
سه نوع هوش مصنوعی
اما در حالی که یک ماشین واقعاً مستقل که کاملاً قادر به مدیریت خود در همه موقعیتها است، جام مقدس تحقیقات در این زمینه است، ما قبلاً پیشرفت قابل توجهی در اجازه دادن به رایانهها برای نشان دادن توانایی انسانمانند هنگام انجام حداقل وظایف بسیار خاص داشتهایم.
برای تمایز بین این سطوح مختلف هوش، محققان در این زمینه اغلب هوش مصنوعی را به دو یا سه نوع تقسیم میکنند:
هوش مصنوعی باریک (ANI)
هوش عمومی مصنوعی (AGI)
ابر هوش مصنوعی (ASI)
ANI اغلب به عنوان هوش مصنوعی ضعیف شناخته می شود، زیرا برای نشان دادن «هوش» یا توانایی انسان مانند در انجام یک کار خاص طراحی شده است. یکی از مرزهای بعدی در ANI به حداکثر رساندن کارایی مدل ها است. این شامل بهینه سازی آموزش، استنتاج، و استقرار، و همچنین افزایش عملکرد هر یک است.
AGI یا هوش مصنوعی قوی به سیستمهایی اطلاق میشود که به طور کلی قادر به تطبیق هوش انسانی هستند (یعنی در بیش از چند کار خاص)، در حالی که یک ابر هوش مصنوعی میتواند از تواناییهای انسان پیشی بگیرد.
در حال حاضر، این مقایسهها عمدتاً به مکاتب فکری منتقل میشوند، زیرا همه مدلهای هوش مصنوعی مستقر نمونههایی از هوش مصنوعی باریک (نه AGI یا ASI) هستند.
تعدادی از عوامل هستند که ظهور AGI را تسریع می کنند، از جمله افزایش دسترسی به داده ها، توسعه الگوریتم های بهتر و پیشرفت در پردازش کامپیوتری.
هوش مصنوعی در فیلم “Her” نمونه ای فرهنگی از AGI است. سامانتا، شخصیت هوش مصنوعی فیلم، افکار و نظرات خاص خود را دارد. او یک ربات تابع نیست، بلکه یک موجود مستقل است. سامانتا قادر به استفاده از تشخیص صدا و گفتار، پردازش زبان طبیعی، بینایی کامپیوتری و غیره است.
این ها نمونههای خوبی از هوش مصنوعی باریک هستند، زیرا نشان میدهند که یک ماشین واقعاً یک کار را به خوبی انجام میدهد. با این حال، زیبایی هوش مصنوعی عمومی این است که میتواند همه این عناصر را در یک سیستم واحد و جامع ادغام کند که میتواند هر کاری را که یک انسان میتواند انجام دهد.
و در حالی که ما دومی را به دست نیاوردهایم، پیشرفت قابلتوجهی با اولی به دست آوردهایم. به عنوان مثال اتومبیل های خودران را در نظر بگیرید. آنها نمونه ای از ANI هستند، زیرا در یک کار خاص (ناوبری) برتری دارند و به طور کلی کاملاً قادر به شناسایی عناصر موجود در محیط خود (سایر خودروها، عابران پیاده و غیره) هستند و آن اطلاعات را در یک تصمیم ترکیب می کنند (به عنوان مثال، نحوه چرخش یا زمان استفاده از ترمز برای جلوگیری از برخورد).
دستیارهای مجازی مانند سیری و دستیار گوگل نمونه هایی از گام های بزرگی هستند که ما در ایجاد سیستم های ANI قوی که قادر به ایجاد ارزش واقعی برای مشاغل و افراد هستند، برداشته ایم.
این دستیارها از تشخیص گفتار استفاده میکنند، یک فناوری مجهز به هوش مصنوعی که به افراد اجازه میدهد دستورات صوتی را وارد کرده و پاسخ دریافت کنند. این از طریق یک مدل یادگیری ماشینی به دست می آید که ساختار زبان را با پردازش امواج صوتی می آموزد و درک می کند.
در هر سیستم هوش مصنوعی، داده ها برای پیش بینی جمع آوری و پردازش می شوند. سپس این داده ها پاک می شوند و به فرمتی تبدیل می شوند که می تواند توسط مدل استفاده شود. سپس مدل یک پیشبینی ایجاد میکند که میتواند به عنوان پاسخی به برخی ورودیها مشاهده شود. ورودی ممکن است یک سوال یا کار باشد و پاسخ را می توان یک پاسخ یا یک راه حل در نظر گرفت.
نمونههای دیگر عبارتند از سیستمهای تشخیص چهره و تصویر، گفتار به متن، ترجمه ماشینی (ترجمه گوگل) و موتورهای توصیه (چگونه آمازون یا نتفلیکس میدانند کدام محصول را میخواهید).
و این همان جایی است که یادگیری ماشین مطرح می شود، زیرا اکثر این پیشرفت ها به لطف یادگیری ماشینی (و یادگیری عمیق) امکان پذیر شده است.
چه AGI ظهور کند یا نه، هوش مصنوعی آینده در همه جا تعبیه خواهد شد و هر بخش از جامعه را تحت تأثیر قرار می دهد، از دستگاه های هوشمند گرفته تا برنامه های وام گرفته تا برنامه های تلفن. با رشد سریع هوش مصنوعی، عملاً همه صنایع در حال بررسی چگونگی استفاده از این فناوری جدید هستند.
یادگیری ماشینی چیست؟
همانطور که در مقدمه این راهنما بحث کردیم، “یادگیری ماشین شاخه ای از علوم کامپیوتر است که به کامپیوترها اجازه می دهد تا به طور خودکار الگوها را از داده ها استنتاج کنند بدون اینکه به صراحت گفته شود که این الگوها چیست.”
به این ترتیب، یادگیری ماشین یکی از راههای دستیابی ما به هوش مصنوعی است – یعنی سیستمهایی که قادر به تصمیمگیری مستقل و شبیه به انسان هستند. متأسفانه، این سیستمها تاکنون تنها به وظایف خاص محدود شدهاند و بنابراین نمونههایی از هوش مصنوعی محدود هستند.
در دو دهه گذشته، بسیاری از مهیجترین برنامههای یادگیری ماشینی از زیرمجموعهای از حوزهای که به آن یادگیری عمیق گفته میشود، آمدهاند. همانطور که در بخش یادگیری عمیق این راهنما مورد بحث قرار گرفت، الگوریتمهای یادگیری عمیق به عملکرد پیشرفتهای در تشخیص تصویر و مشکلات پردازش زبان طبیعی دست یافتهاند. آنها همچنین وعده های باورنکردنی در پیش بینی و تقویت مشکلات یادگیری نشان داده اند. بیایید به عقب برگردیم و به چگونگی ارتباط هوش مصنوعی، ML و DL با یکدیگر نگاه کنیم.
هوش مصنوعی و ML چگونه به هم مرتبط هستند؟
گرافیک زیر رابطه بین هوش مصنوعی، یادگیری ماشینی و یادگیری عمیق را به خوبی توضیح می دهد.
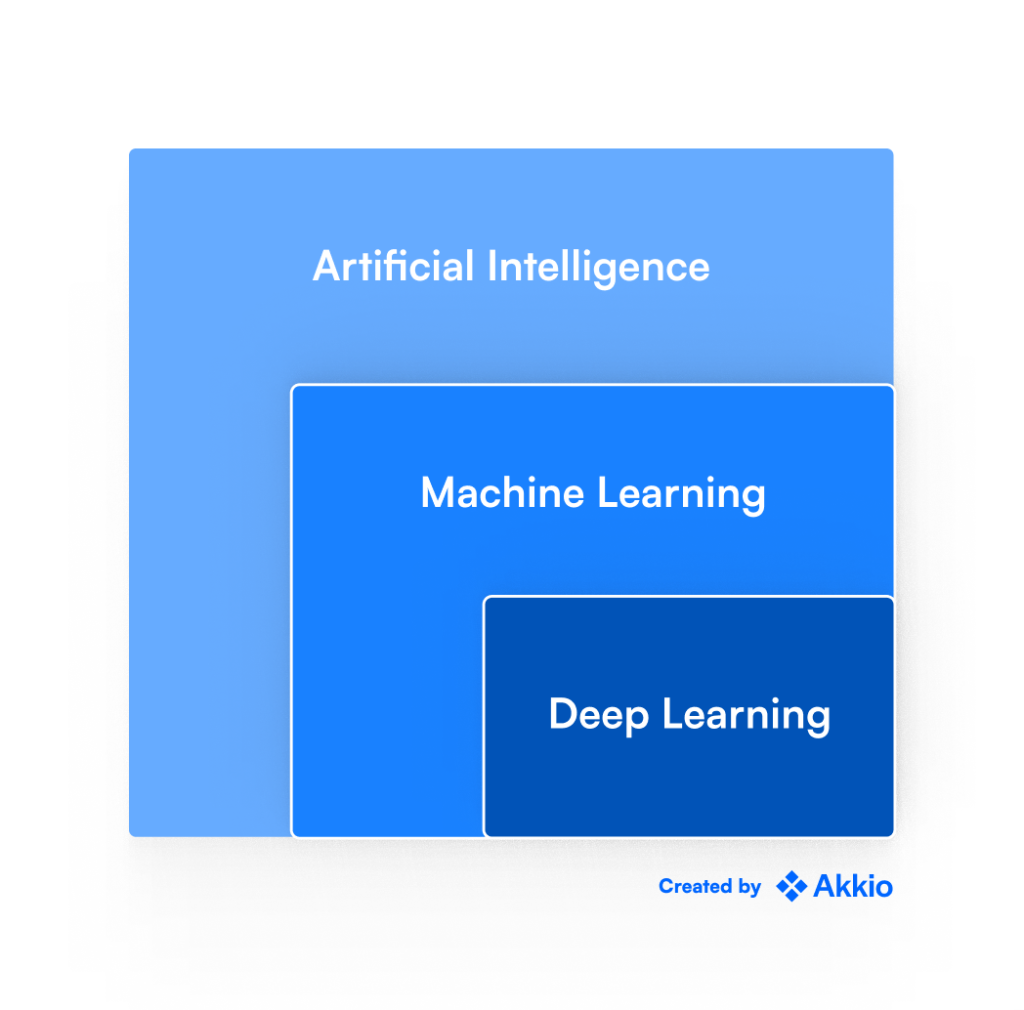
هوش مصنوعی کلیترین مورد از این سه مورد است و تقریباً میتوان آن را به عنوان هدف اصلی این حوزه تحقیقاتی در نظر گرفت: ایجاد سیستمهایی که قادر به تقلید از تصمیمگیری انسان هستند.
یک تصور غلط رایج این است که هوش مصنوعی در حال یادگیری است. در حقیقت، هوش مصنوعی توسط انسان ها برای تکمیل وظایف و ارائه پیش بینی ها برنامه ریزی شده است. هوش مصنوعی می تواند هوش را تقلید کند، اما نمی تواند به طور مستقل مانند یک شخص یاد بگیرد. هدف مهندسان هوش مصنوعی امروزه این است که ماشینها را بیشتر شبیه انسان و کمتر شبیه ماشینها بکنند.
یکی دیگر از اهداف امروزی محققان هوش مصنوعی این است که هوش مصنوعی رفتاری شبیه انسان داشته باشد. این امر به ویژه چالش برانگیز است، زیرا رفتار به عنوان محصول مشترک استعداد و محیط در نظر گرفته می شود که مفاهیم کاملاً متفاوتی بین افراد و ماشین ها هستند.
یادگیری ماشینی یکی از راههای دستیابی به هوش مصنوعی است، در حالی که یادگیری عمیق زیرمجموعهای از الگوریتمهای یادگیری ماشینی است که بیشترین امید را در برخورد با مشکلات مربوط به دادههای بدون ساختار، مانند تشخیص تصویر و زبان طبیعی نشان دادهاند.
یادگیری ماشین معمولاً به عنوان بخشی از سیستم های ترکیبی استفاده می شود. سیستمهای ترکیبی ترکیبی از هوش انسان و ماشین هستند که به دنبال ترکیب بهترینهای هر دو جهان هستند، مانند مدلهای یادگیری ماشینی که پیشبینیهایی را برای انسان ارسال میکنند تا تجزیه و تحلیل شوند.
مهم است که بین یادگیری ماشین و هوش مصنوعی تمایز قائل شویم، زیرا یادگیری ماشین تنها وسیلهای برای ایجاد سیستمهای هوشمند مصنوعی نیست – فقط موفقترین سیستمها تا کنون.
هوش مصنوعی نمادین
برای مثال، در سالهای اولیه تحقیق در این زمینه، محققان بر روی ساخت سیستمهای هوش مصنوعی نمادین متمرکز شدند – که به آن هوش مصنوعی کلاسیک یا هوش مصنوعی قدیمی (GOFAI) نیز گفته میشود.
این رویکرد برای ایجاد سیستم های هوشمند بر نمایش جهان به عنوان مجموعه ای از نمادها، ترجمه مسائل دنیای واقعی به گزاره های نمادین، و سپس اجازه دادن به کامپیوتر برای استفاده از منطق گزاره ای برای حل این مشکلات تمرکز دارد.
این تلاشها بر اساس مشاهده این بود که انسانها (و زبانهای ما) از نمادها برای نمایش هر دو شی در دنیای واقعی و نحوه ارتباط آنها با یکدیگر استفاده میکنند. “جان” و “پیتزا” نماد هستند، در حالی که “خوردن” رابطه بین این دو شی / نماد است.
فرض کنید میتوانیم کل جهان (یا حداقل، تمام اطلاعات مربوط به یک حوزه خاص، مانند پزشکی) را در چنین نمادها و روابطی نشان دهیم. در آن صورت، یک کامپیوتر می تواند این مشکلات را با استفاده از منطق حل کند.
همچنین میتوانیم گزارههای مختلف را با استفاده از قواعد if-then به هم پیوند دهیم. برای مثال، اگر گرسنه هستید (جان) پس بخورید (جان، پیتزا). این نمونه ای از یک هوش مصنوعی نمادین مبتنی بر قوانین بسیار ساده است.
البته، در حالی که این مثال ساده فقط از چند نماد و یک قانون استفاده می کند، یک سیستم کامپیوتری واقعی می تواند میلیاردها نماد، گزاره و قانون را ذخیره کند. چنین سیستمهای مبتنی بر قاعده پایه و اساس آنچه به عنوان سیستمهای خبره شناخته میشوند، ابزارهای هوش مصنوعی هستند که بر سلسله مراتبی از قوانین برای ارائه راهحل برای مشکلات تکیه دارند.
برای مثال، پزشک را در نظر بگیرید که بیمار را تشخیص می دهد. این تشخیص ها اغلب مبتنی بر قانون نیز هستند: به عنوان مثال، اگر بیمار علائم X و Y داشته باشد، اگر قند خون او بیشتر از Z باشد، پس به بیماری A مبتلا هستند. ، و پیشگیری محققان نشان داده اند که الگوریتم ها در طبقه بندی سلول ها به عنوان سرطانی یا غیر سرطانی بهتر از انسان هستند.
یا مشکل درخواست وام را در نظر بگیرید که در مقاله یادگیری ماشینی به آن پرداختیم. گروهی از کارشناسان به راحتی می توانند این مشکل را در یک سری نمادها و قوانین نشان دهند (به عنوان مثال، اگر امتیاز اعتباری > X و مبلغ وام < Y و سپس وام را تأیید کند). سپس میتوان از آن برای ایجاد یک سیستم خبره هوش مصنوعی استفاده کرد که به طور بالقوه میتواند جایگزین پزشک یا افسر وام برای تصمیمگیری شود.
هوش مصنوعی نمادین از چندین مزیت نسبت به یادگیری ماشینی برخوردار است. در حالی که سیستمهای یادگیری ماشین تشخیص الگو را بر روی دادههای تاریخی انجام میدهند، سیستمهای نمادین فقط به یک متخصص نیاز دارند تا فضای مشکل را بر اساس نمادها، گزارهها و قوانین تعریف کند. بنابراین، به هیچ داده آموزشی نیاز ندارد.
علاوه بر این، از آنجایی که سیستمهای هوش مصنوعی نمادین سلسله مراتبی از قوانین قابل خواندن برای انسان را تشکیل میدهند، تفسیر آنها بسیار سادهتر از مثلاً شبکههای عصبی عمیق هستند که بهطور معروف غیرشفاف هستند و تفسیر آنها دشوار است.
در نهایت، یک هوش مصنوعی نمادین ایدهآل، با تمام دانشی که یک انسان از جهان دارد، به طور بالقوه میتواند نمونهای از یک هوش مصنوعی عمومی (یا فوقالعاده) باشد که قادر به استدلال واقعی مانند یک انسان است.
با این گفته، در حالی که از لحاظ نظری منطقی است که استدلال کنیم که ما میتوانیم به طور بالقوه همه دانش را به عنوان نماد بیان کنیم، واقعیت این است که درک ما از جهان بهطور باورنکردنی پیچیده است و به صراحت تمام دانش بشری و عقل سلیم را به عنوان مجموعهای از نمادها و روابط بیان میکند. یک کار هرکولی خواهد بود.
نمایش برخی از اطلاعات به عنوان نماد نیز ممکن است دشوار باشد. به عنوان مثال، طبقه بندی تصاویر را در نظر بگیرید. چگونه می توان یک “2” را در شکل تصویر به عنوان یک نماد توصیف کرد؟ در حالی که شبکه های عصبی در این وظایف برتری دارند، ترجمه ساده مشکل به یک سیستم نمادین دشوار است.
این یکی از محدودیتهای اصلی تحقیقات نمادین هوش مصنوعی در دهههای 70 و 80 بود. این سیستم ها اغلب شکننده در نظر گرفته می شدند (یعنی قادر به رسیدگی به مشکلاتی که خارج از هنجار بودند)، فاقد عقل سلیم و در نتیجه راه حل های «اسباب بازی» بودند.
این محدودیتها یکی از محرکهای اولیه اولین «زمستان هوش مصنوعی» بودند، دورهای که اکثر بودجهها برای سیستمهای هوش مصنوعی برداشته شد، زیرا تحقیقات نتوانست به طور رضایتبخشی به این مشکلات رسیدگی کند.
در نتیجه، جدای از برخی کاربردهای خاص، هوش مصنوعی نمادین عموماً به نفع یادگیری ماشینی از مد افتاده است، که بر وظایف خاص (یعنی هوش مصنوعی باریک) تمرکز میکرد اما راهحلهای بسیار قویتری ارائه میکرد.
پیشرفتها در قدرت محاسباتی و تکثیر دادهها در عصر اینترنت نیز یک عامل تقویت کننده قابل توجه در فعال کردن سیستمهای یادگیری ماشینی بوده است، که عملکرد آنها اغلب به مقدار (و کیفیت) دادههای موجود محدود میشود.
با این حال، در سالهای اخیر، محققان شروع به ترکیب سیستمهای یادگیری ماشین، بهویژه شبکههای عصبی، با هوش مصنوعی نمادین کردهاند تا از نقاط قوت هر دو این رویکردها برای هوش مصنوعی استفاده کنند. این به عنوان محاسبات عصبی نمادین شناخته می شود.
کاربردهای ML: رگرسیون
بسیاری از برنامههای تجاری به پیشبینی یک مقدار پیوسته نیاز دارند. به عنوان مثال، “ارزش مادام العمر یک مشتری با سن و سطح درآمد معین چقدر است؟”، یا “احتمال ریزش مشتری چقدر است؟” اینها معمولاً به عنوان مشکلات رگرسیون نامیده می شوند.
در این مقاله، چندین الگوریتم یادگیری ماشینی را که برای حل مسائل رگرسیون استفاده میشوند، مرور خواهیم کرد. در حالی که ما ریاضیات را به طور عمیق پوشش نمی دهیم، حداقل به طور خلاصه به شکل کلی ریاضی این مدل ها می پردازیم تا درک بهتری از شهود پشت این مدل ها به شما ارائه دهیم.
رگرسیون خطی
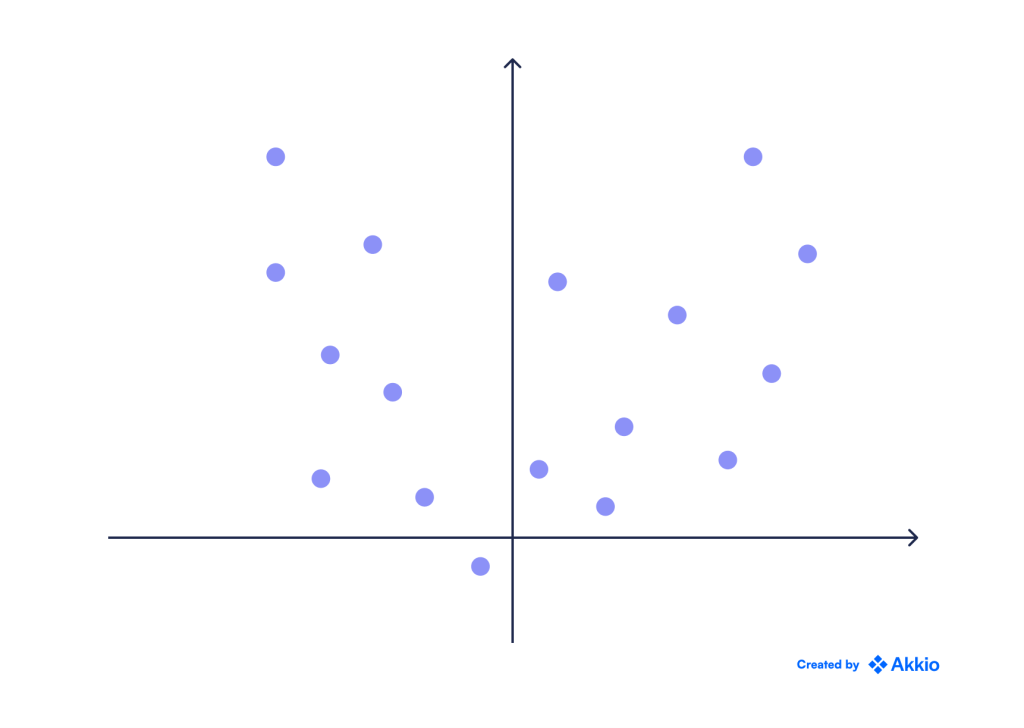
رایج ترین روش برای حل مسائل رگرسیون به عنوان رگرسیون خطی شناخته می شود. فرض کنید اطلاعات زیر در مورد رابطه بین pH و اسید سیتریک برای تعیین کیفیت شراب به شما داده شده است.
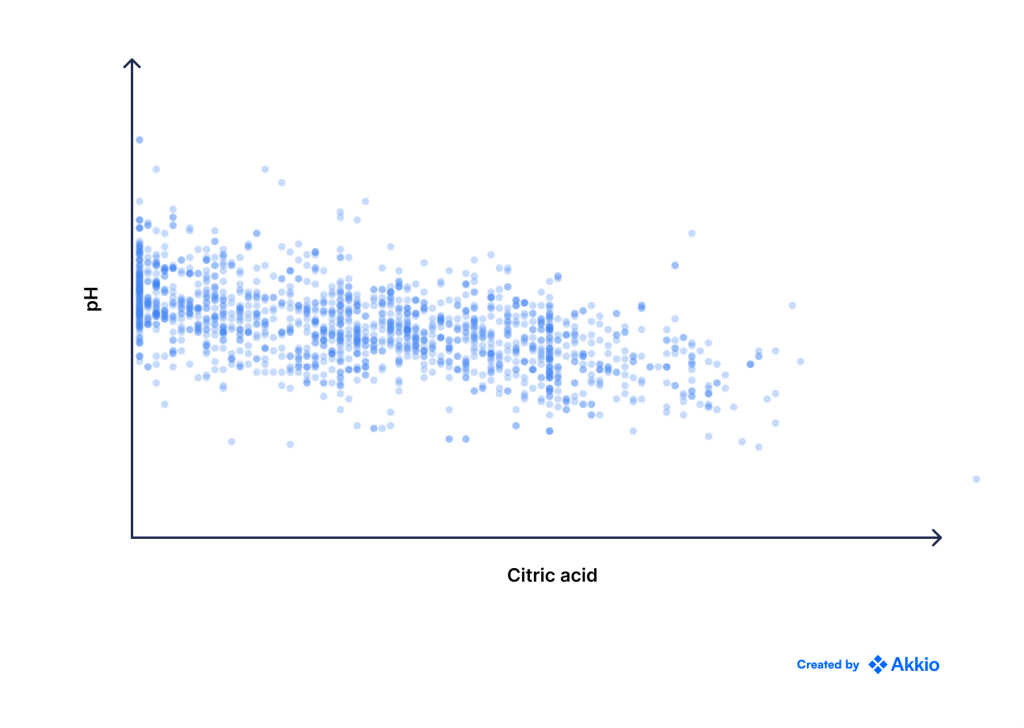
شما می توانید به وضوح یک رابطه خطی بین این دو مشاهده کنید، اما مانند تمام داده های واقعی، مقداری نویز نیز وجود دارد. از آنجایی که رابطه خطی است، مدل سازی آن با استفاده از یک خط مستقیم منطقی است.
ممکن است از ریاضی دبیرستان به یاد بیاورید که معادله یک خط مستقیم به صورت زیر است:
جایی که
![]()
y پاسخ است،
x پیش بینی کننده است،
m شیب خط (یا ضریب/وزن x) است و
c وقفه y است،
میتوانیم این را به پیشبینیکنندههای چندگانه به صورت زیر تعمیم دهیم، که شکل کلی رگرسیون خطی نیز است:
جایی که
![]()
y^ پیشبینی مدل ما است
β₀ وقفه است
βᵢ ضریب پیش بینی xᵢ-امین است و
p تعداد کل پیشبینیکنندهها است
اما به طور بالقوه میتوانیم خطوط مستقیم زیادی ترسیم کنیم و به دلیل نویز، کاملاً مشخص نیست که کدام یک «بهترین خط» است. مثلا از بین سه خط زیر کدام یک بهتر است؟
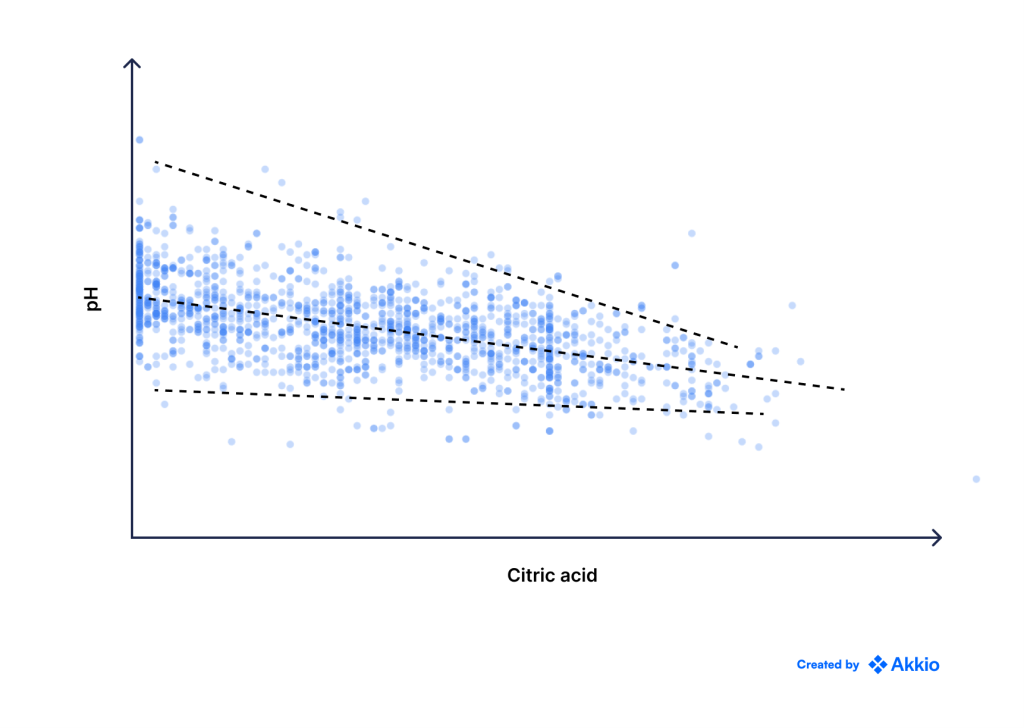
این امر مستلزم آن است که معیاری برای آنچه که از نظر ریاضی «خوب» در مقابل «بد» در نظر گرفته میشود، تعریف کنیم.
از آنجایی که ما از این مدل برای پیشبینی مقادیر استفاده میکنیم، منطقی است که از خطای پیشبینیهایمان به عنوان معیار خود استفاده کنیم، جایی که خطا به عنوان تفاوت بین مقدار واقعی و پیشبینی ما تعریف میشود. خطی که خطای پیشبینی کلی را به حداقل میرساند «خوب» است، در حالی که خطی که خطای کلی بزرگی دارد «بد» است.
روش های مختلفی برای محاسبه خطاها وجود دارد. برای اهداف خود، از مجموع مربعات خطاها (SSE) استفاده خواهیم کرد. به عنوان یک مثال ساده از این موضوع، مثال زیر را برای پیش بینی آب و هوا در نظر بگیرید:
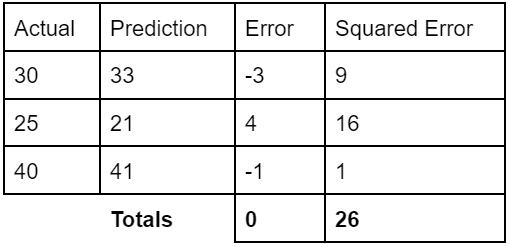
در این مرحله، ممکن است تعجب کنید که چرا ما مربع خطاها را در نظر می گیریم، و نه فقط مقدار واقعی را. این به این دلیل است که ما نمی خواهیم خطاهای منفی و مثبت یکدیگر را خنثی کنند.
اگر فقط مقادیر خطا را در مثال بالا جمع کنیم، 4 – 3 – 1 = 0 به دست میآوریم. این نشان میدهد که مدل بینقص است و به ما حس اعتماد کاذب نسبت به مدلمان میدهد. استفاده از خطاهای مربعی از این اتفاق جلوگیری می کند.
فرمول ریاضی زیر مجموع مجذور خطاهای فوق الذکر را توصیف می کند. هنگام استفاده از مجموع مربعات خطاها، درک این نکته مهم است که این نشانگر کاملی نیست که یک مدل چقدر با داده ها مطابقت دارد، اما درک آن ساده است، و بنابراین به طور گسترده استفاده می شود، زیرا فقط بر سه مقدار متکی است: عدد. از نقاط داده، مقادیر واقعی و پیش بینی ها.
جایی که
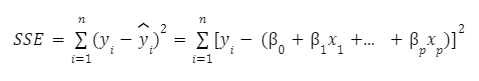
n تعداد نقاط داده ای که داریم
yᵢ مقدار واقعی پاسخ برای نقطه داده i است
yᵢ پیشبینی ما برای نقطه داده i است
بنابراین، از بین تمام خطوط ممکنی که می توانیم ترسیم کنیم، خطی را با کمترین SSE انتخاب می کنیم. به این تابع هدف می گویند—یعنی مقداری که می خواهیم کمینه یا حداکثر کنیم. در این مورد، ما می خواهیم SSE را به حداقل برسانیم.
در حالی که در اینجا وارد جزئیات ریاضی نمیشویم، این مشکل را میتوان به راحتی با استفاده از نظریه بهینهسازی حل کرد، بنابراین به ما امکان میدهد «بهترین» خط را پیدا کنیم که مجموع مربعات خطاها را به حداقل میرساند.
هنگامی که بهترین خط را پیدا کردیم، میتوانیم هر نقطه ورودی جدید را با درون یابی مقدار آن از خط مستقیم پیشبینی کنیم. برای مثال، در حالی که هیچ یک از نقاط داده ما اسید سیتریک 0.8 ندارند، میتوانیم پیشبینی کنیم که وقتی مقدار اسید سیتریک 0.8 است، pH ~3 است.
در حالی که مثال بالا با تنها یک پاسخ و یک پیشبینی کننده بسیار ساده بود، ما به راحتی میتوانیم همان منطق را به مسائل پیچیدهتر شامل ابعاد بالاتر (یعنی پیشبینیکنندههای بیشتر) تعمیم دهیم.
روشهای رگرسیون غیرخطی
مشکلات رگرسیون در دنیای واقعی اغلب غیرخطی هستند. راه های زیادی برای مقابله با چنین مشکلاتی وجود دارد، چه با گسترش خود مدل رگرسیون خطی یا با استفاده از ساختارهای مدل سازی دیگر.
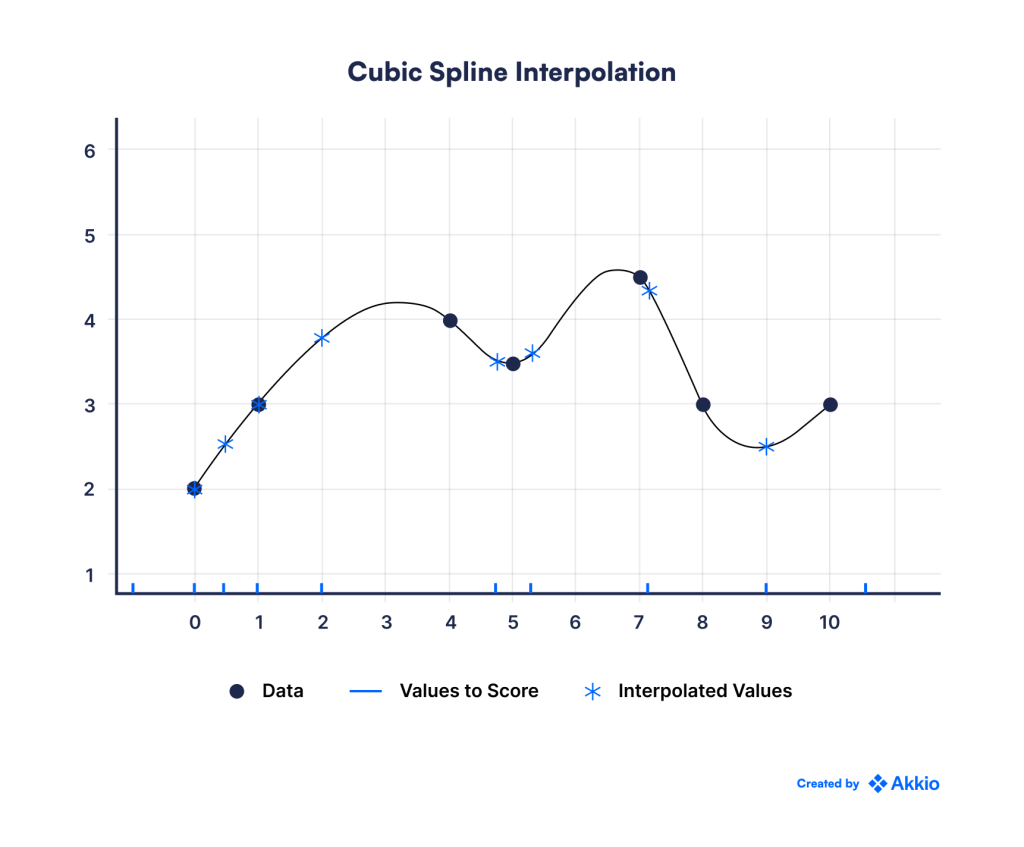
به عنوان مثال، می گوییم داده هایی که داریم به این صورت است:
در حالی که مقداری نویز وجود دارد، می توانید ببینید که این یک منحنی درجه دوم است. بیایید بگوییم می دانیم که رابطه واقعی با معادله به دست می آید:
![]()
ما به راحتی میتوانیم مدل رگرسیون خطی را به سادگی با گرفتن مربع متغیر وابسته و اضافه کردن آن به عنوان پیشبینیکننده دیگری برای مدل رگرسیون خطی به این مسئله بسط دهیم. ما میتوانیم همین کار را برای عبارتهای مرتبه بالاتر انجام دهیم، و به آن رگرسیون چند جملهای گفته میشود.
سایر روشهای پیچیدهتر شامل استفاده از اسپلاین است. در حالی که ما با جزئیات وارد نظریه یا ریاضیات پشت این موضوع نمیشویم، در یک سطح بنیادی، spline به ما اجازه میدهد تا توابع غیرخطی مختلف را در قسمتهای مختلف فضای ورودی قرار دهیم، در حالی که از صاف بودن توابع اطمینان حاصل میکنیم (یعنی متصل هستند). ) در مرزهای بین این مناطق.
نتیجه یک مدل بسیار انعطافپذیر است که میتواند دادههای غیرخطی را نزدیکتر جا دهد. با این حال، این ممکن است به قیمت تطبیق بیش از حد باشد، زیرا ممکن است مدل به جای الگوهای واقعی با نویز تصادفی مطابقت داشته باشد. در نتیجه، خطوط و رگرسیون چند جملهای باید با دقت مورد استفاده قرار گیرند و با استفاده از اعتبارسنجی متقاطع ارزیابی شوند تا اطمینان حاصل شود که مدلی که آموزش میدهیم میتواند تعمیم یابد.
همچنین ممکن است از روشهای ناپارامتریک برای مشکلات رگرسیون استفاده کنیم. سادهترین آنها ممکن است فقط رگرسیون K-نزدیکترین همسایه باشد. در این روش، با توجه به دادههای تاریخی و نقطه داده جدیدی که میخواهیم برای آن پیشبینی کنیم، به سادگی نزدیکترین نقاط داده k به این نقطه جدید را پیدا میکنیم و مقدار آن را میانگین این نقاط k پیشبینی میکنیم.
همچنین میتوانیم از درختهای تصمیم برای مشکلات رگرسیون استفاده کنیم. در اینجا، ما داده ها را بر اساس مجموعه ای از معیارها به زیر مجموعه های مختلف تقسیم می کنیم. سپس ممکن است یک مقدار ثابت به هر گره برگ به عنوان پیش بینی آن اختصاص دهیم (مثلاً میانگین تمام نقاط داده متعلق به آن گره برگ). مثال زیر را در مورد استفاده از رگرسیون درخت تصمیم برای پیشبینی تعداد ساعتهای بازی بر اساس شرایط آب و هوایی مختلف ببینید:
روش دیگر، ما همچنین میتوانیم یک مدل رگرسیون خطی جداگانه برای هر یک از گرههای برگ قرار دهیم.
مانند بسیاری دیگر از مشکلات یادگیری ماشین، ما همچنین میتوانیم از یادگیری عمیق و شبکههای عصبی برای حل مسائل رگرسیون غیرخطی استفاده کنیم.
پیش بینی احتمالات با رگرسیون لجستیک
بیایید ایده پیش بینی یک متغیر پیوسته را به احتمالات گسترش دهیم. فرض کنید میخواستیم احتمال لغو اشتراک مشتری در سرویس ما را پیشبینی کنیم.
از آنجایی که احتمال یک متغیر پیوسته است، به طور طبیعی خود را به رگرسیون گسترش می دهد. با این حال، این یک متغیر پیوسته است که توسط دو قید محدود شده است: یک احتمال نه میتواند منفی باشد و نه بیشتر از 1. رگرسیون خطی منظم قادر به رعایت این محدودیتها نیست، و بنابراین مدل لجستیک متولد شد.
رگرسیون لجستیک گسترش رگرسیون خطی است که خط بین رگرسیون و طبقه بندی را در بر می گیرد. بر اساس همان اصل رگرسیون خطی کار میکند، اما با یک تفاوت کلیدی: پاسخ، گزارش طبیعی احتمال وقوع یک رویداد است.
شانس، در آمار، به نسبت احتمال وقوع یک رویداد به احتمال رخ ندادن آن اشاره دارد:
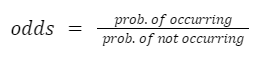
به عنوان مثال، می گویند احتمال پیروزی بارسلونا در بازی بعدی خود 30٪ است. سپس، شانس پیروزی آنها 3/7 یا 3:7 است. این نامگذاری نیز در قمار مورد استفاده قرار میگیرد، اگرچه سایتهای قمار اغلب شانسهایی را در برابر یک رویداد نشان میدهند و نه شانسی برای آن. شانس مقابل بارسلونا در این مورد 7:3 خواهد بود.
گزارش شانس (یا log-odds) اغلب به عنوان logit(p) نامیده میشود، جایی که p احتمال وقوع یک رویداد است. بنابراین مدل لجستیک با معادله زیر نشان داده می شود:
![]()
از نظر آماری، برجستهترین جنبه استفاده از لاگ طبیعی شانس این است که در حالی که خروجی مدل رگرسیون هنوز محدود نشده است، وقتی شانسهای ورود به سیستم را به احتمالات برمیگردانیم، این احتمالات بین 0 تا 1 محدود میشوند، بنابراین مشکل ما حل میشود!
در حالی که ما وارد جزئیات ریاضی نمیشویم، اما میتوانید نموداری از احتمال خروجی p را در زیر مشاهده کنید که مقدار متغیر مستقل تغییر میکند:
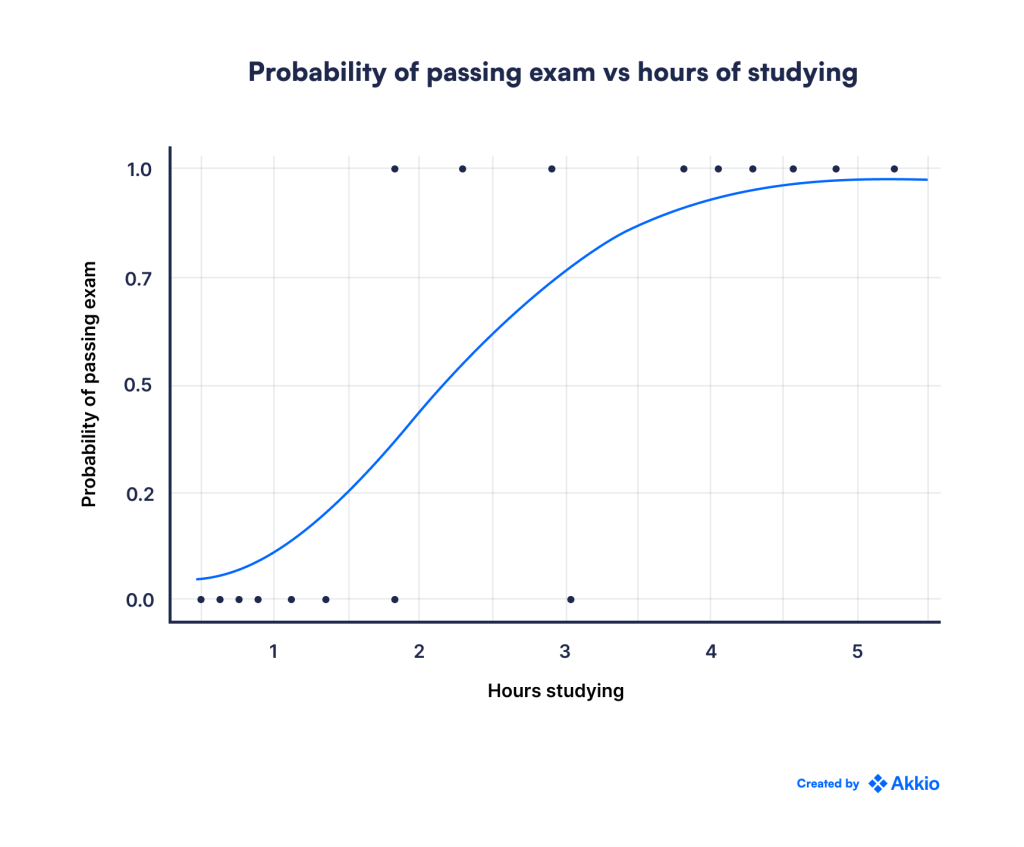
بنابراین، ما با موفقیت مدل رگرسیون خطی را برای پیشبینی احتمالات گسترش دادیم. زمانی که تخمینی برای احتمال وقوع یک رویداد داشته باشیم، طبقهبندی فقط یک قدم با شما فاصله دارد.
اگر احتمال خاصی را به عنوان آستانه تعیین کنیم، میتوانیم هر نقطه داده (به عنوان مثال، هر مشتری) را به یکی از دو کلاس طبقهبندی کنیم. انتخاب این آستانه تا حد زیادی به برنامه بستگی دارد.
به عنوان مثال، یک خودروساز لوکس که با حاشیه های بالا و حجم پایین کار می کند، ممکن است بخواهد بسیار فعال باشد و شخصاً با احتمال 20 درصد از کار افتادن مشتریان خود را بررسی کند. اگر انحراف از نظر مأموریت حیاتی نیست یا ما به سادگی منابع لازم برای رسیدگی به مشتریان فردی را نداریم، ممکن است بخواهیم این آستانه را بسیار بالاتر (مثلاً 90٪) تعیین کنیم، بنابراین فقط در مورد فوری ترین مشتریان بالقوه هشدار داده می شود.
کاربردهای ML: طبقه بندی
در بخش قبل، به نمونههایی از مشکلات رگرسیون پرداختیم، جایی که میخواهیم یک متغیر پیوسته را پیشبینی کنیم. دومین نوع مشکل یادگیری تحت نظارت، طبقهبندی است، جایی که میخواهیم هر نمونه را به یکی از دو (یا بیشتر) دستهبندی کنیم.
به عنوان مثال، یک بانک ممکن است بخواهد تعیین کند که آیا متقاضی وام وام خود را بازپرداخت می کند یا خیر. یا ممکن است یک ارائه دهنده ایمیل بخواهد سیستمی بسازد که هرزنامه را از صندوق ورودی شما فیلتر کند.
در هر دوی این موارد، ما فقط دو کلاس/دسته ممکن داریم، اما امکان رسیدگی به مشکلات با چندین گزینه نیز وجود دارد. برای مثال، یک سیستم امتیازدهی سرنخ ممکن است بخواهد بین لیدهای گرم، خنثی و سرد تمایز قائل شود. مشکلات بینایی رایانه اغلب مشکلات چند طبقه ای نیز هستند، زیرا ما می خواهیم چندین نوع اشیاء (ماشین ها، افراد، علائم راهنمایی و رانندگی و غیره) را شناسایی کنیم.
در این مقاله، برخی از الگوریتمهای مورد استفاده برای مسائل طبقهبندی را بررسی میکنیم. با این حال، تمرکز در اینجا بر ایجاد شهود خواهد بود، و بنابراین ما ریاضیات پشت این الگوریتمها را با جزئیات پوشش نمیدهیم. ما همچنین برای سادگی فقط بر روی مشکلات طبقه بندی باینری (یعنی مواردی که فقط دو گزینه دارند) تمرکز خواهیم کرد.
K-Nearest Neighbours (KNN)
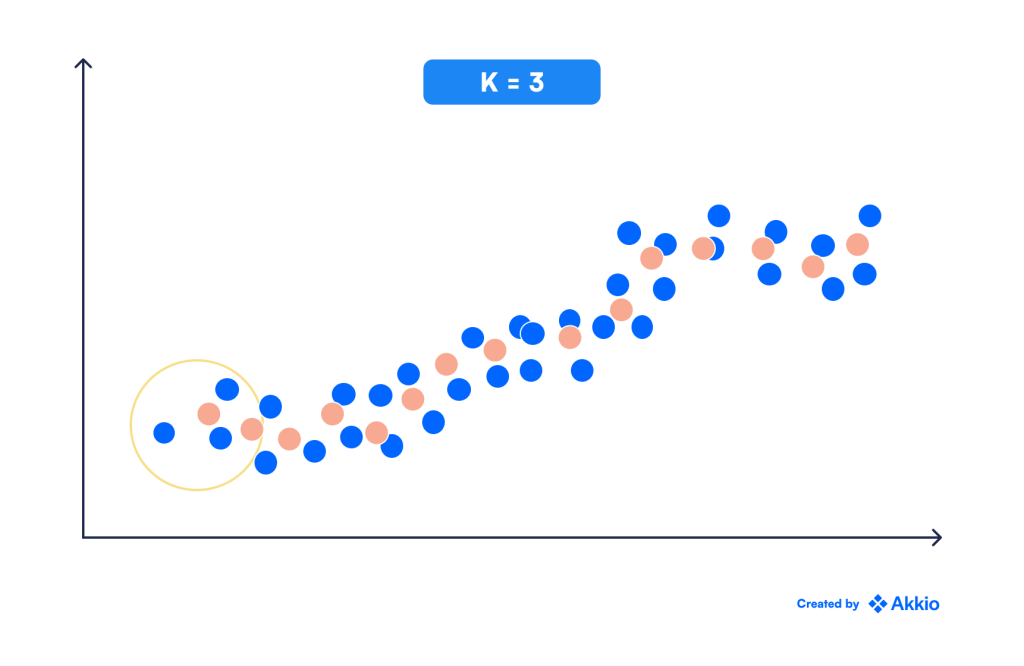
یکی از سادهترین الگوریتمهای طبقهبندی، طبقهبندی KNN است. فرض کنید ما داده های تاریخی با برچسب ها و یک نقطه جدید داریم که می خواهیم برچسب آن را تعیین کنیم. در این روش، ما به سادگی نزدیکترین نقطه k به نقطه جدید را پیدا میکنیم و برچسب آن را به عنوان حالت (متداولترین کلاس) این نقاط k اختصاص میدهیم.
برای مثال، تصویر زیر را در نظر بگیرید. اگر k=3، برچسب نقطه سبز یک مثلث قرمز است زیرا در بین سه نقطه نزدیک به آن، اکثریت (⅔) مثلث های قرمز هستند.
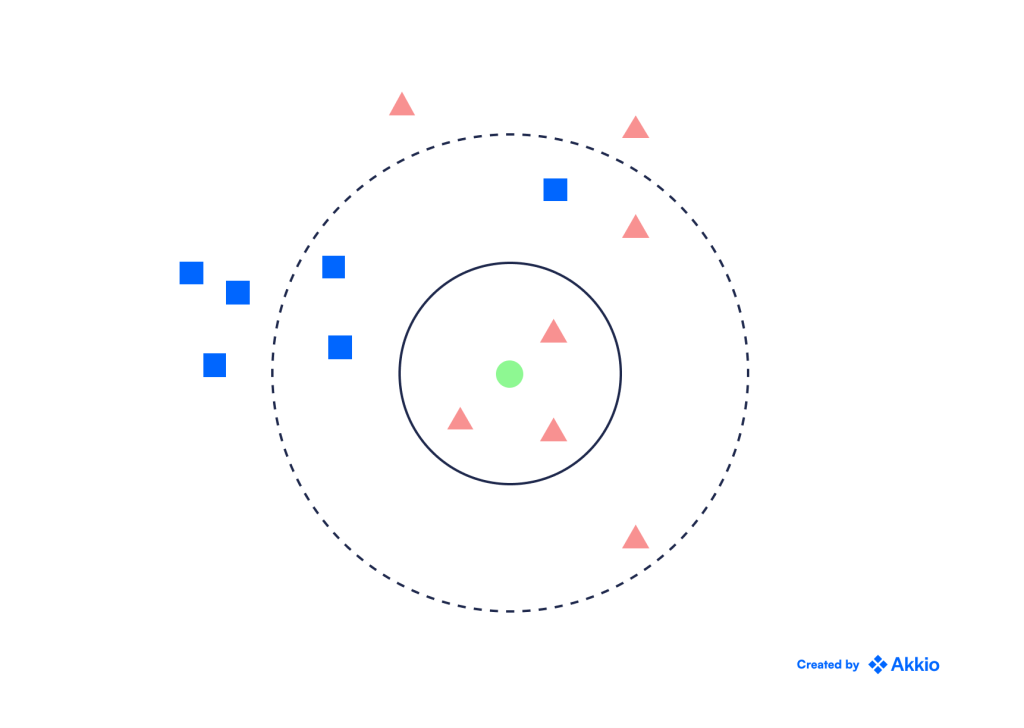
همانطور که در بخش رگرسیون بحث کردیم، الگوریتم KNN میتواند مسائل رگرسیون غیرخطی را نیز حل کند.
ماشینهای بردار پشتیبانی (SVM)
یکی دیگر از الگوریتم های طبقه بندی رایج SVM است. مثال زیر را در نظر بگیرید که در آن می خواهیم ایمیل های اسپم را فیلتر کنیم. محور x تعداد دفعاتی است که کلمه خرید در ایمیل ظاهر می شود و محور y تعداد افرادی است که همان ایمیل را دریافت کرده اند. هنگامی که رسم می شود، داده ها به شکل زیر هستند:
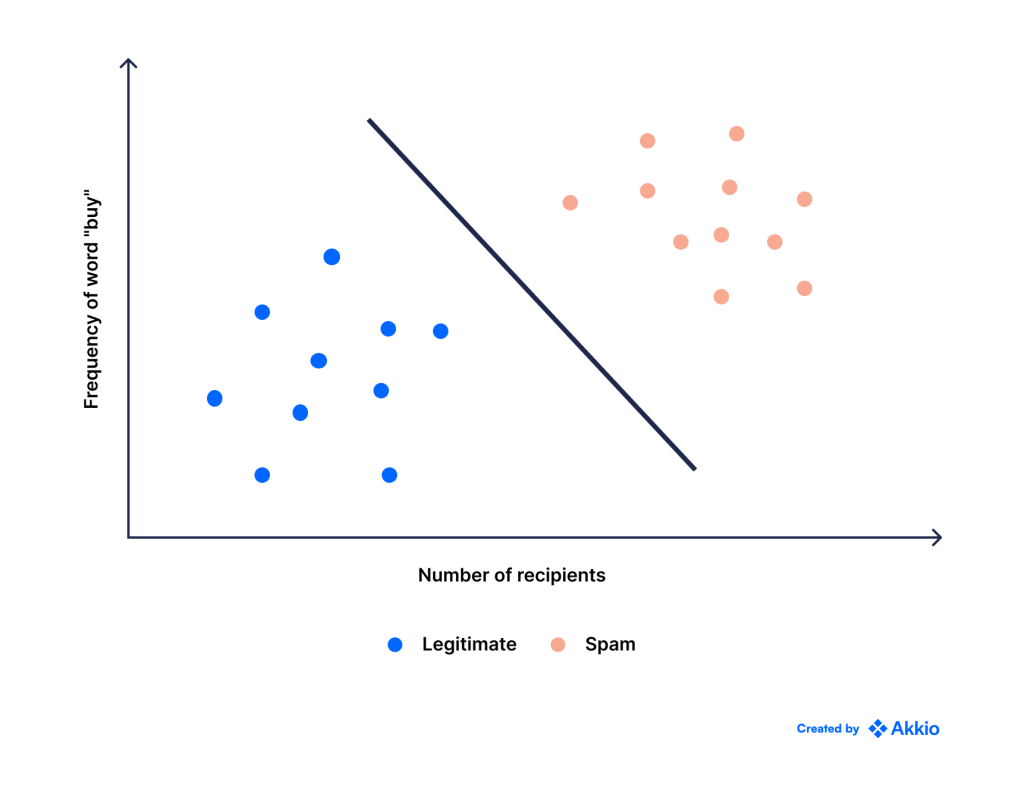
نقاط آبی ایمیل های قانونی هستند و نقاط قرمز اسپم هستند. ایمیلهای اسپم احتمالاً از شما میخواهند چیزهایی بخرید و برای افراد بیشتری ارسال میشوند، بنابراین منطقی است که ایمیلهایی که برای تعداد زیادی از افراد ارسال میشوند با ذکر کلمه «خرید» زیاد، هرزنامه باشند.
مهمتر از همه، ما می بینیم که می توانیم به وضوح این دو کلاس را با استفاده از یک خط مستقیم از هم جدا کنیم، اما مانند رگرسیون خطی، این سوال ایجاد می کند: کدام خط بهترین است؟
همانطور که در زیر نشان داده شده است، می توانیم خطوط ممکن زیادی را ترسیم کنیم که همه آنها کاملاً بین دو کلاس از هم جدا می شوند.
بنابراین، ممکن است بخواهیم به این فکر کنیم که چه چیزی یک خط را بهتر از خط دیگر می کند. این تا حدودی به مشکلی که ما در تلاش برای حل آن هستیم بستگی دارد و بعداً به این نکته خواهیم پرداخت.
با این حال، در حال حاضر، یک معیار معقول ممکن است انتخاب خطی باشد که حاشیه بین دو کلاس را به حداکثر میرساند – یعنی خطی که تا حد امکان از افراطیترین نمونههای هر کلاس دور باشد.
این سؤال دیگری را ایجاد می کند: چگونه می توانیم این را به جای اینکه آن را با چشم انجام دهیم به یک مسئله ریاضی تبدیل کنیم؟ نمودار زیر را در نظر بگیرید.
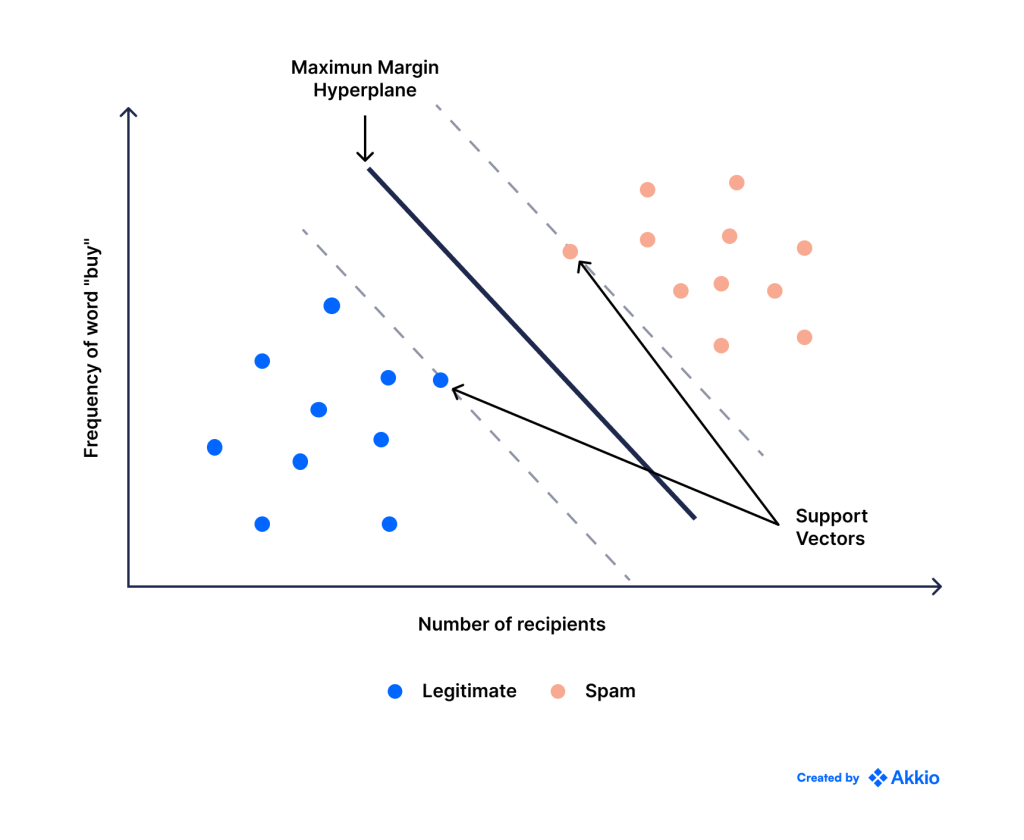
میتوانیم «بهترین» خط را با ترسیم دو خط که فقط بیرونیترین نقاط هر کلاس را لمس میکنند، پیدا کنیم. همچنین توجه داشته باشید که هر دوی این خطوط موازی یکدیگر هستند. این خطوط بردارهای پشتیبانی نامیده می شوند. از این رو نام الگوریتم است.
سپس خط “بهترین” خطی است که با هر دوی این خطوط موازی است و همچنین از آنها فاصله دارد (یعنی فاصله آن از هر یک برابر است). فاصله بین بردارهای پشتیبان و خط طبقهبندیکننده حاشیه نامیده میشود و ما میخواهیم این را به حداکثر برسانیم.
این رایج ترین (یا پیش فرض) روشی است که در آن SVM بهترین خط طبقه بندی کننده را انتخاب می کند. با این حال، ممکن است همیشه این روش ایده آل برای انجام کارها نباشد.
به عنوان مثال، فرض کنید ما در حال کار بر روی تعیین خوش خیم یا بدخیم بودن تومور بودیم. در این صورت هزینه اشتباه برای هر کلاس یکسان نیست. اگر یک تومور بدخیم را به عنوان خوش خیم طبقه بندی کنیم، ممکن است به قیمت جان بیمار تمام شود، در حالی که اشتباه گرفتن یک تومور خوش خیم به عنوان بدخیم ممکن است فقط به آزمایش های بیشتر نیاز داشته باشد. واضح است که یک اشتباه از دیگری بدتر است.
بسته به کاربرد و میزان دقتی که میخواهیم انجام دهیم، ممکن است وزن بیشتری را به هر یک از انواع اشتباه اختصاص دهیم. به این ترتیب، ممکن است تصمیم بگیریم خط را از یک کلاس دورتر کنیم یا حتی عمداً برخی از نقاط داده را به اشتباه برچسب گذاری کنیم، فقط به این دلیل که می خواهیم در مورد اشتباه بسیار محتاط باشیم.
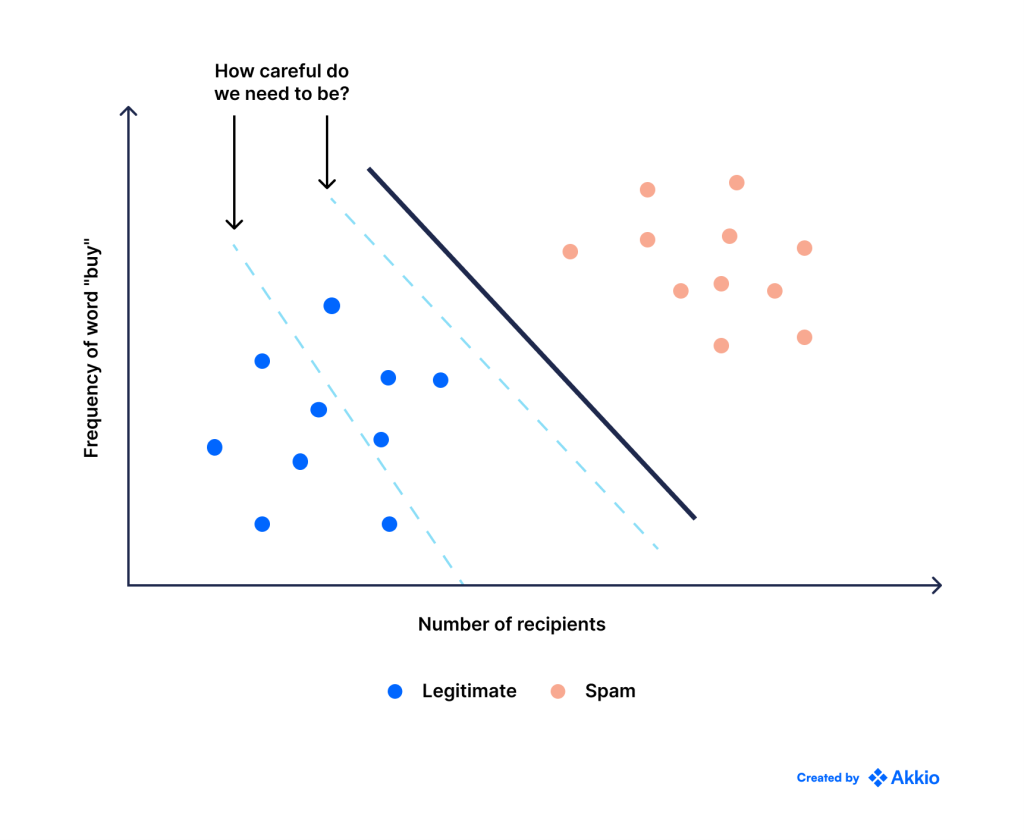
در مرحله بعد، بیایید سناریوهایی را در نظر بگیریم که در آن دو کلاس نمی توانند به طور تمیز از طریق یک خط مستقیم از هم جدا شوند.
طبقه بندی کننده های نرم در مقابل سخت
گاهی اوقات، ممکن است نتوان با استفاده از یک خط مستقیم، نقاط را کاملاً طبقه بندی کرد. پس میتوانیم به روشهای غیرخطی متوسل شویم (که بعداً بحث شد)، اما فعلاً فقط به خطوط مستقیم پایبند باشیم.
در آن صورت، ممکن است مایل به استفاده از یک طبقهبندی ناقص باشیم. این طبقهبندیکننده نرم نیز نامیده میشود، زیرا همه نقاط را به درستی طبقهبندی نمیکند. از سوی دیگر، یک طبقهبندیکننده سخت به نمونههایی که تا کنون بحث کردهایم اشاره میکند، که تمام نقاط داده را کاملاً طبقهبندی میکند.
به مثال زیر توجه کنید:
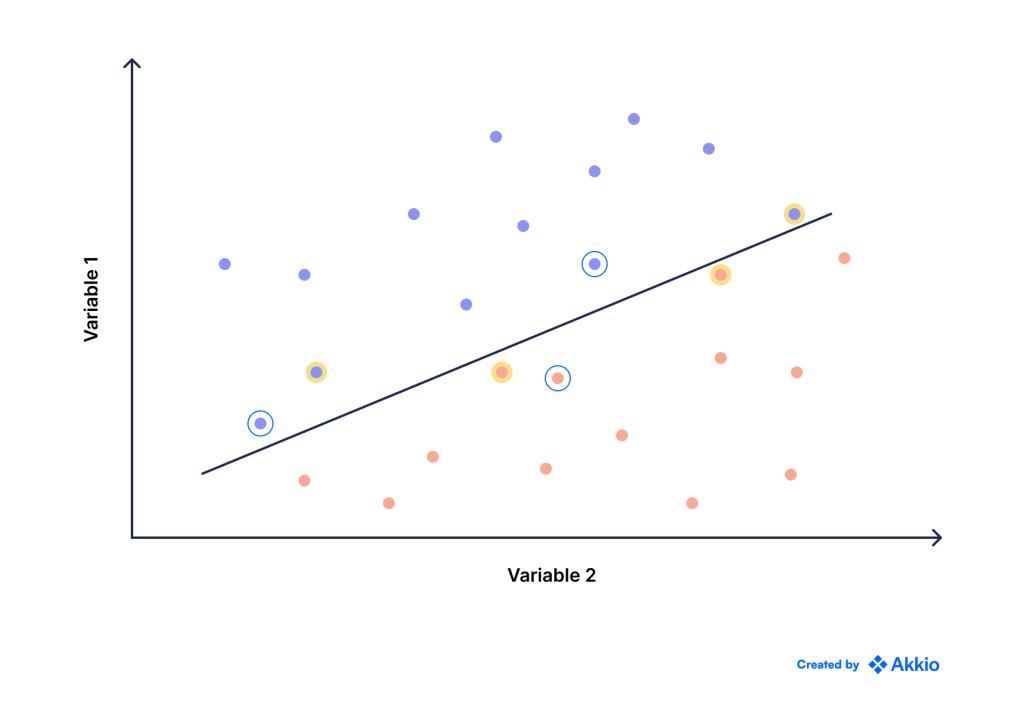
در تصویر بالا، میبینیم که طبقهبندیکننده نرمی که انتخاب کردهایم، سه نقطه را به اشتباه طبقهبندی میکند (که با رنگ زرد مشخص شده است). در عین حال، دو نقطه آبی و دو نقطه قرمز (به رنگ آبی دایره شده) را نیز می بینیم که به شدت به خط نزدیک هستند و تقریباً اشتباه هستند. بنابراین، طبقه بندی کننده ما دارای حاشیه بسیار کمی بین دو کلاس است.
طبقهبندیکننده دیگری را که میتوانیم برای همان دادهها ترسیم کنیم، در نظر بگیرید:
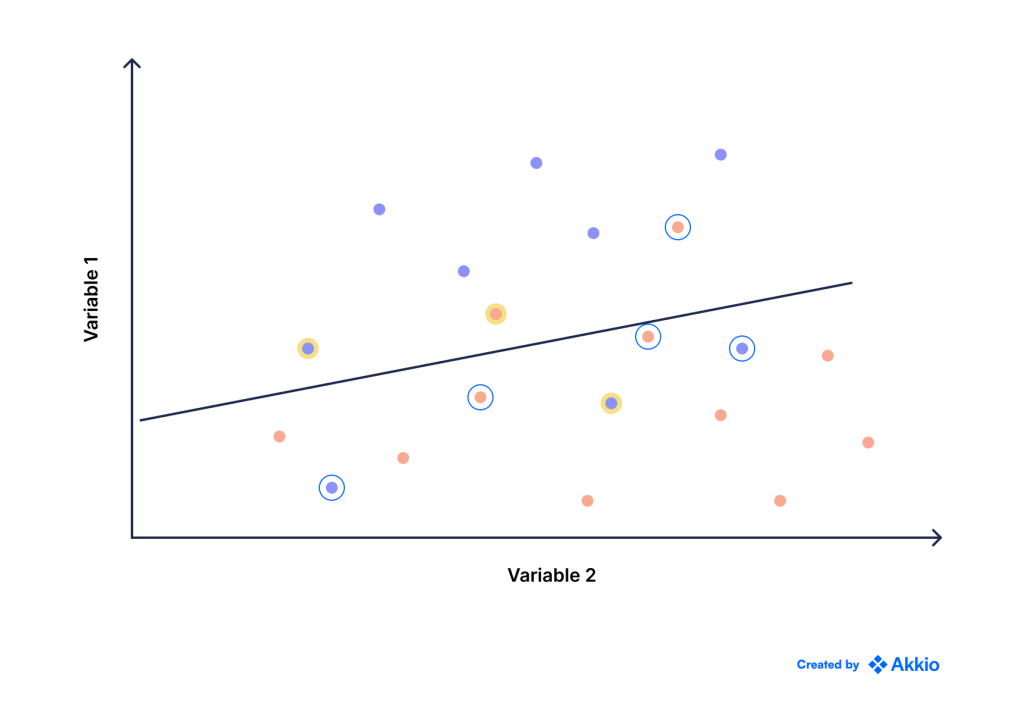
در این مورد، ما پنج نقطه اشتباه طبقه بندی شده داریم (در مقایسه با سه نقطه قبلی)، اما خط دارای حاشیه گسترده تر و نقاط بسیار کمی است که نزدیک به خط هستند یا بسیار نزدیک به خط هستند.
این یک مبادله ذاتی با طبقهبندیکنندههای نرم را نشان میدهد. میتوانیم خطاها را به حداقل برسانیم یا حاشیه بین دو کلاس را به حداکثر برسانیم.
در حالی که جزئیات ریاضی را در اینجا نشان نمیدهیم، میتوانیم وزنهای متفاوتی را به هر یک از این گزینهها اختصاص دهیم، بسته به اینکه دقت بالاتر در مقایسه با داشتن یک مرز تمیزتر و کمتر مبهم اهمیت دارد.
این نمونهای از یک فراپارامتر مدل است: متغیری که برای الگوریتم مشخص میکنیم و شکلی را که مدل ما خواهد داشت را تعریف میکند یا به نوعی محدود میکند.
طبقه بندی کننده های غیر خطی SVM
حال به مثال زیر توجه کنید:
در این حالت، می بینیم که در حالی که یک خط مستقیم نمی تواند این نقاط را جدا کند، یک دایره می تواند. چگونه می توانیم این مشکل را حل کنیم؟ همانطور که در بالا دیدیم، یک گزینه ممکن است استفاده از روش های غیرخطی مانند طبقه بندی KNN یا درختان طبقه بندی باشد.
از آنجایی که اینها روشهای ناپارامتریک هستند و شکل خاصی را برای مدل مشخص نمیکنند (مثلاً اینکه باید یک خط مستقیم باشد)، بهویژه برای مسائل غیرخطی مناسب هستند.
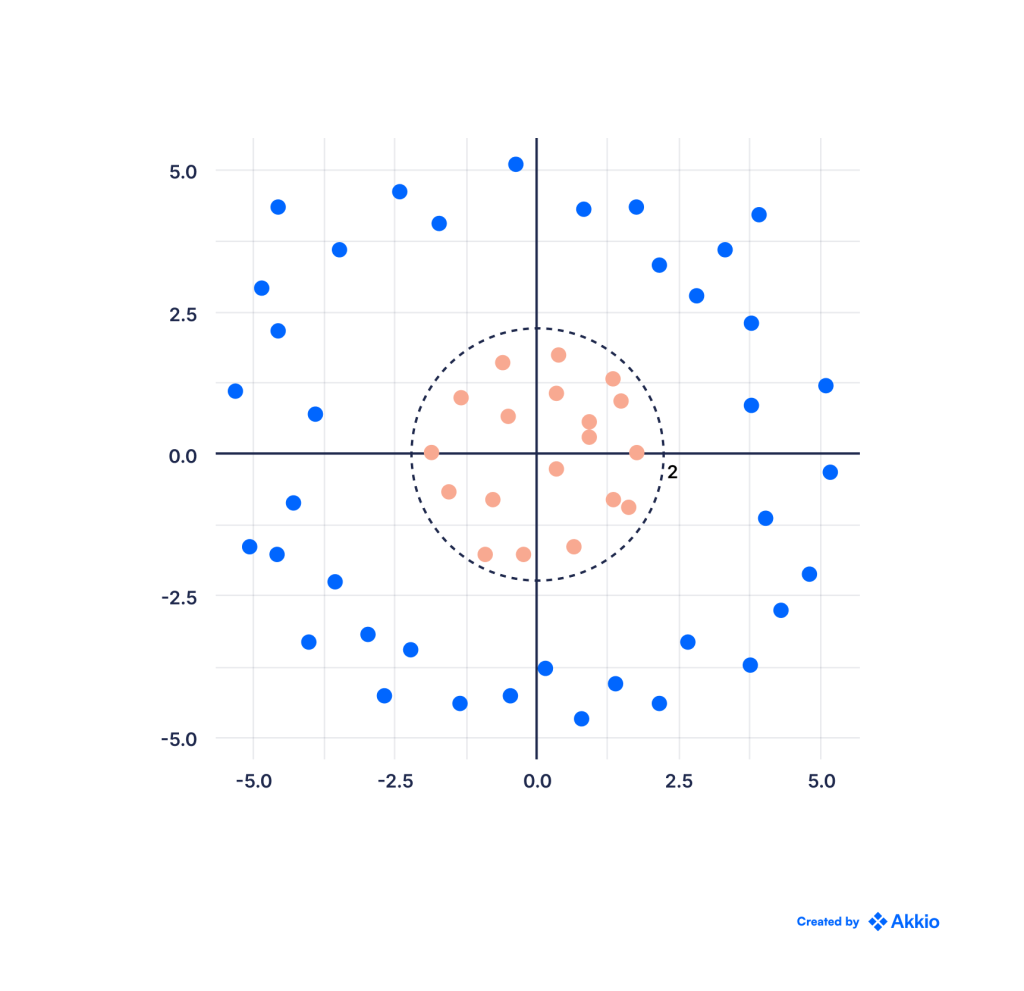
با این حال، SVM همچنین میتواند برای حل این مشکل با تبدیل دادهها برای دستیابی به جداسازی خطی بین کلاسها گسترش یابد. به عنوان مثال، میتوانیم ببینیم که تمام نقاط داخل یک دایره به شعاع 2 قرمز و نقاط خارج از آن آبی هستند.
در یک مورد ساده مانند این، اگر داده ها را از مختصات دکارتی به قطبی تبدیل کنیم. نمودار حاصل در زیر نشان داده شده است، که در آن محور x فاصله شعاعی از مبدا و محور y زاویه بر حسب رادیان است:
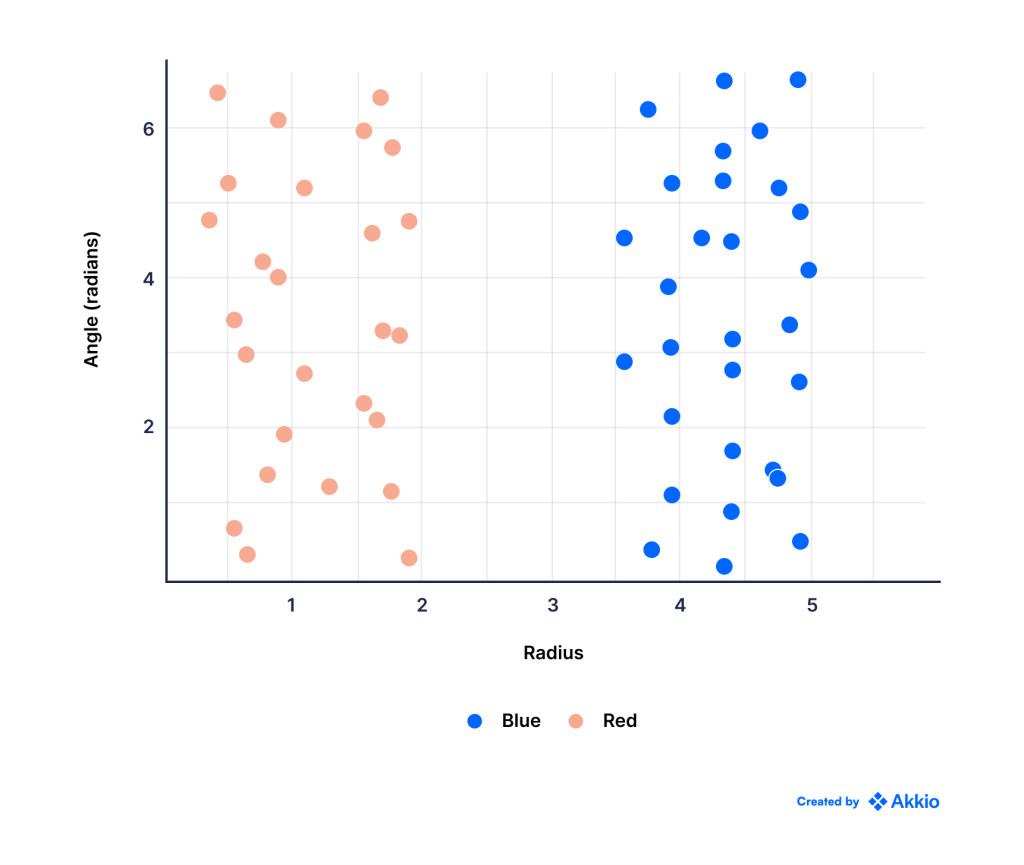
همانطور که مشاهده می شود، اکنون کلاس ها به راحتی با استفاده از یک خط مستقیم از هم جدا می شوند. بنابراین، ما به سادگی الگوریتم SVM را به این نسخه تبدیل شده از داده ها تغذیه می کنیم.
در سناریوهای پیچیده تر، به خصوص زمانی که مشکلات چند بعدی داریم و نمی دانیم که طبقه بندی کننده ایده آل مثلاً یک دایره است، ممکن است ندانیم از کدام تبدیل استفاده کنیم. در موارد دیگر، تبدیل ممکن است از نظر محاسباتی ناکارآمد باشد.
در این موارد میتوانیم با افزودن ابعاد بیشتر به آن مشکل را تبدیل کنیم. این به عنوان ترفند هسته یا SVM کرنل نامیده میشود و به ما اجازه میدهد تا مرزهای طبقهبندی غیرخطی مانند زیر ایجاد کنیم:
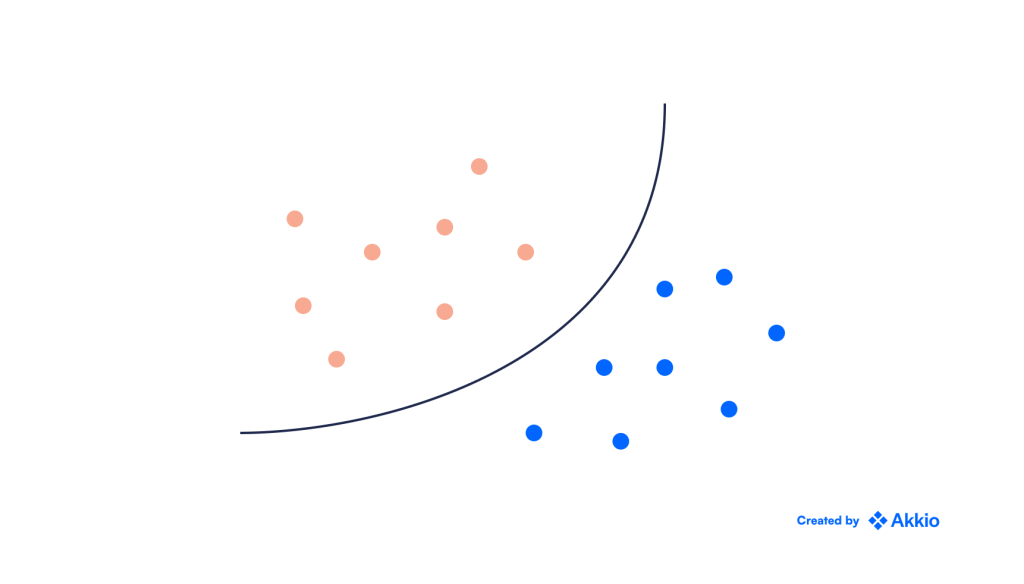
توضیح مکانیک یا ریاضی چگونگی و چرایی کارکرد SVM کرنل از حوصله این مقاله خارج است. با این حال، دانستن جزئیات مهمی است تا بتوانید درک جامعی از انواع مشکلاتی که الگوریتم SVM میتواند حل کند داشته باشید.
روش های هسته باید با SVM با احتیاط استفاده شوند. با افزودن ابعاد بیشتر به مسئله و اجازه دادن به مرزهای غیرخطی، مدلی انعطافپذیرتر ایجاد میکنیم. این به راحتی می تواند منجر به بیش از حد برازش شود.
درختان طبقه بندی
یکی دیگر از روشهای حل مسائل طبقهبندی – و روشی که برای مسائل غیرخطی بسیار مناسب است – استفاده از درخت تصمیم است.
از آنجایی که درختهای تصمیم را میتوان برای مسائل طبقهبندی و رگرسیون استفاده کرد (به بخش رگرسیون مراجعه کنید)، گاهی اوقات به الگوریتم CART (درخت طبقهبندی و رگرسیون) اشاره میشود.
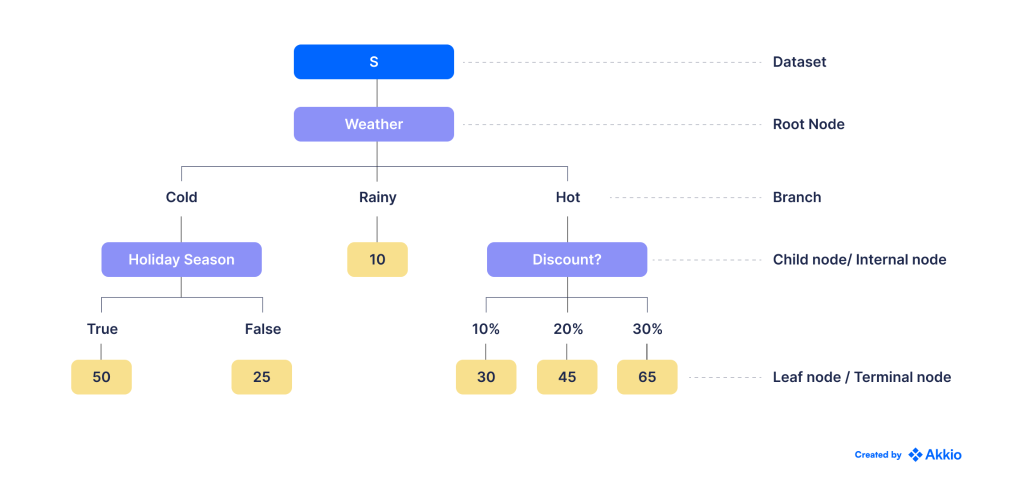
در این روش داده ها را بر اساس یک سری سوالات باینری (بله/خیر) به زیر مجموعه های کوچکتر و کوچکتر تقسیم می کنیم. درخت تصمیم زیر را برای تصمیم گیری در مورد اینکه آیا باید فوتبال بازی کنیم یا نه، بر اساس تأثیر آب و هوا در بازی های گذشته در نظر بگیرید:
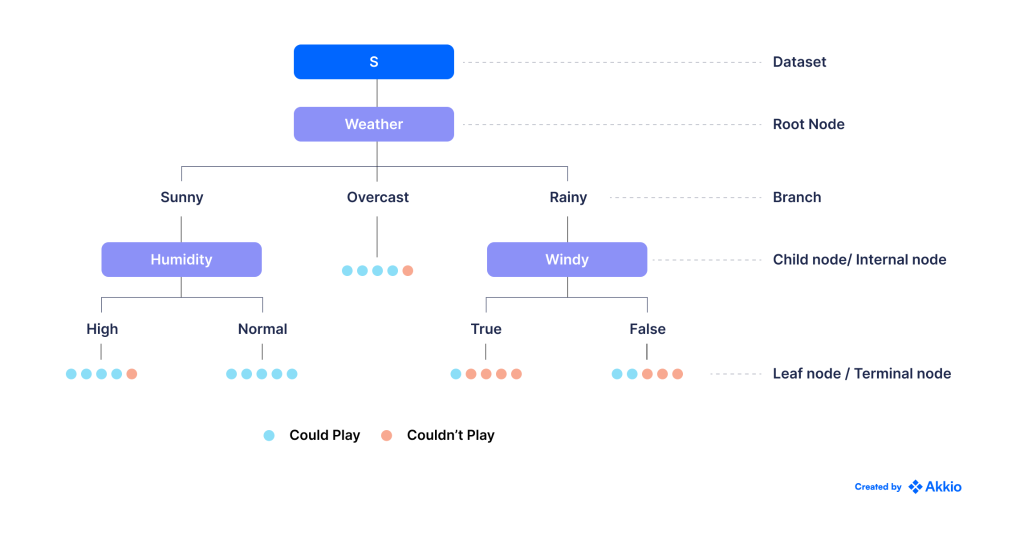
توپها در گرههای برگ نشان میدهند که آیا ما توانستهایم یک بازی (آبی) را با شرایط آب و هوایی داده شده با موفقیت به پایان برسانیم یا اینکه بازی باید به دلیل آب و هوای نامناسب (قرمز) قطع شود.
می بینیم که در بیشتر روزهای بارانی با باد، مجبور شدیم بازی هایمان را لغو کنیم. به این ترتیب، حالت این گره برگ قرمز است، و ما هر روز بارانی و بادی آینده را به عنوان قرمز طبقهبندی میکنیم (یعنی احتمالاً در آن روزها نباید بازی کنیم).
توجه داشته باشید که درختهای تصمیم نیز نمونهای عالی از تفاوت روشهای یادگیری ماشینی با اشکال سنتیتر هوش مصنوعی هستند. شاید به خاطر داشته باشید که در بخش «تفاوت بین یادگیری ماشینی و هوش مصنوعی» در مورد چیزی به نام «سیستمهای خبره» بحث کردیم که سلسله مراتبی از قوانین if/else هستند که به رایانه اجازه میدهند تصمیم بگیرند.
درخت تصمیم نیز سلسله مراتبی از قوانین باینری است، اما تفاوت اصلی بین این دو این است که قوانین در یک سیستم خبره توسط یک متخصص انسانی تعریف میشوند. از سوی دیگر، درختهای تصمیم به خودی خود مشخص میکنند که معیارهای تقسیم در مرحله (یعنی قوانین) باید چه باشند – به همین دلیل است که میگوییم ماشین در حال یادگیری است.
چگونه این کار را انجام می دهد؟ ممکن است متوجه شده باشید که هر یک از گره های برگ عمدتاً از یک کلاس تشکیل شده است – برای مثال، گره Sunny + Normal Humidity عمدتا آبی است، در حالی که گره Rainy + Windy عمدتا قرمز است.
این بر اساس طراحی است. در هر مرحله از ساختن درخت تصمیم، کامپیوتر به تمام گزینه های ممکنی که دارد نگاه می کند و معیار تقسیم را انتخاب می کند که ناخالصی گره های بعدی را به حداقل می رساند – یعنی سعی می کند اطمینان حاصل کند که هر یک از گره ها دارای نقاطی هستند که متعلق به آنهاست. در صورت امکان فقط به یک کلاس.
البته، اگر به رایانه اجازه دهیم که دادهها را به زیر مجموعههای کوچکتر و کوچکتر تقسیم کند (به عنوان مثال، یک درخت عمیق)، در نهایت ممکن است به سناریویی برسیم که در آن هر گره برگ فقط یک (یا تعداد بسیار کمی) نقطه داده را شامل میشود. این ممکن است منجر به تطبیق بیش از حد شود. بنابراین حداکثر عمق مجاز یکی از مهمترین هایپرپارامترها هنگام استفاده از روشهای مبتنی بر درخت است.
یادگیری عمیق (Deep Learning)
یادگیری عمیق نمونه عالی دیگری از روش طبقه بندی است. در واقع، مدلهای یادگیری عمیق در حل مسائل با چندین کلاس عالی هستند.
آن ها همچنین در برخورد با روابط غیرخطی و مسائل غیرساختیافته مؤثر هستند، زیرا میتوانند تعاملات انتزاعیتر بین اصطلاحات مختلف را نشان دهند.
در بخش «یادگیری ماشین چیست»، مثالی از بانکی را در نظر گرفتیم که تلاش میکند تعیین کند آیا متقاضی وام احتمالاً نکول میکند یا خیر. این نمونه ای از مشکلی است که در آن داده های نسبتاً ساختار یافته ای داریم. ما برای هر متقاضی، مقادیر خاصی از معیارهای مختلف را می دانیم که فکر می کنیم برای حل مشکل آنها مهم و مرتبط هستند (مانند درآمد، امتیاز اعتباری و غیره). این معیارها اغلب به عنوان ویژگی ها یا پیش بینی کننده ها شناخته می شوند.
اما مشکل تشخیص چهره چطور؟ فرض کنید ما دو عکس از یک فرد داریم که به جهات مختلف نگاه می کند. اگر این دو تصویر را صرفاً به عنوان رشته ای از پیکسل ها به یک الگوریتم کلاسیک ML تغذیه کنیم، ممکن است تشخیص ندهد که آنها یک شخص هستند زیرا رشته پیکسل هایی که دریافت می کند ممکن است بر اساس شرایط رعد و برق، جهتی که در آن رعد و برق دریافت می کند، کاملاً متفاوت باشد. شخص نگاه می کند و غیره.
در عوض، برای ما منطقیتر خواهد بود که ابتدا ویژگیهای مفید را از تصویر استخراج کنیم و سپس آنها را به عنوان ورودی الگوریتم تغذیه کنیم.
به عنوان مثال، ممکن است بخواهیم رنگ پوست، شکل صورت، طول بینی، رنگ چشم و غیره را مشخص کنیم. از آنجایی که بدون در نظر گرفتن شرایط نوری یا جهت چهره آنها یکسان باقی می مانند، این ممکن است راه حل بسیار قوی تری باشد.
با این حال، این مشکل دیگری را ایجاد می کند زیرا ممکن است به الگوریتم دیگری برای یادگیری ماشینی نیاز داشته باشیم تا، به عنوان مثال، بین صورت و موی فرد تمایز قائل شویم. هنگامی که مو را شناسایی کردیم، ممکن است به یک الگوریتم یادگیری ماشین دوم برای تمایز بین انواع مختلف رنگ مو نیاز داشته باشیم (زیرا رنگ موها مجزا نیستند و موهای “قرمز” در واقعیت می توانند رنگ های بسیار متفاوتی داشته باشند).
به این ترتیب، ممکن است لازم باشد مسئله را به لایههای زیرمشکلات کوچکتر تقسیم کنیم (همچنین با استفاده از یادگیری ماشین حل شدهاند) تا ابتدا ویژگیهای ساختاریافته مرتبط را استخراج کنیم قبل از اینکه بتوانیم آنها را به الگوریتم نهایی که در واقع چهرهها را طبقهبندی میکند تغذیه کنیم.
از سوی دیگر، یادگیری عمیق سعی میکند این مشکل را دور بزند، زیرا نیازی به تعیین این ویژگیهای میانی ندارد. درعوض، میتوانیم به سادگی تصویر خام و بدون ساختار را به آن بدهیم و او به تنهایی متوجه شود که این ویژگیهای مرتبط چه میتواند باشد.
با انجام این کار، دو مزیت قابل توجه در مقایسه با الگوریتمهای یادگیری ماشین کلاسیک ارائه میکند:
ما ممکن است همیشه ندانیم که کدام ویژگی ها مرتبط هستند. به عنوان مثال، آیا طول مژه ها مرتبط است؟ به جای اینکه خودمان بفهمیم کدام ویژگیها مرتبط هستند، یک مدل یادگیری عمیق میتواند این کار را برای ما انجام دهد و به طور بالقوه ویژگیهایی را که ممکن است هرگز به آنها فکر نکردهایم شناسایی کند. و حتی اگر بدانیم ویژگی های مربوطه چیست، دیگر نیازی به صرف زمان برای استخراج این ویژگی ها نداریم زیرا شبکه عصبی این کار را برای ما انجام می دهد.
همچنین به همین دلیل است که الگوریتم های یادگیری عمیق اغلب جعبه سیاه در نظر گرفته می شوند. پیچیدگی ساختار آنها و تعداد زیاد لایهها در آنها به این معنی است که ما نمیتوانیم دقیقاً اطلاعاتی را در مورد ویژگیهای خاص استخراج کنیم، همانطور که ممکن است با یک مدل رگرسیون خطی انجام دهیم، که در آن ضریب برای هر ویژگی اطلاعات مستقیم و به راحتی قابل تفسیر را در مورد رابطه خطی میدهد. بین ویژگی ها و پاسخ.
چرا شبکه های عصبی عمیق هستند؟
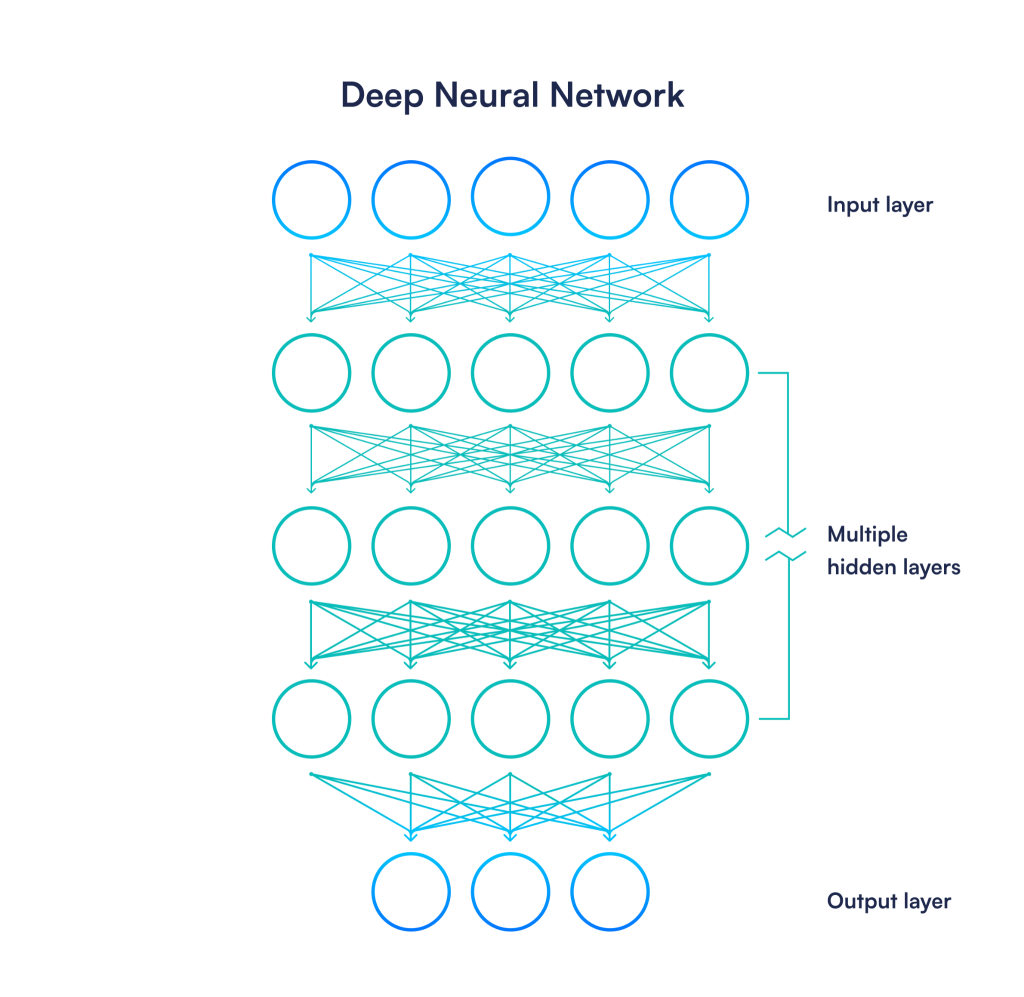
همانطور که قبلاً بحث کردیم، یک شبکه عصبی زمانی “عمیق” است که حاوی چندین لایه باشد. در حالی که پزشکان مختلف ممکن است دقیقاً در آستانه شبکه عصبی «عمیق» متفاوت باشند، یک شبکه عصبی با بیش از سه لایه اغلب به عنوان «عمیق» در نظر گرفته میشود.
با این حال، این سوال پیش میآید که چرا شبکههای عصبی باید عمیق باشند؟
برای پاسخ به این سوال، به یاد بیاورید که چگونه، در بخش قبل، در مورد اینکه حل یک مشکل تشخیص چهره ممکن است نیاز به ایجاد خط لوله ای با چندین لایه از مشکلات فرعی به منظور استفاده از الگوریتم های کلاسیک ML داشته باشد، بحث کردیم.
خوب، معلوم می شود که الگوریتم های یادگیری عمیق نیز کم و بیش اینگونه کار می کنند. به عنوان مثال، در یک مسئله طبقهبندی تصویر، تحقیقات نشان داده است که هر یک از لایهها (یا گروهی از آنها) تمایل به استخراج قطعات خاصی از اطلاعات در مورد تصویر دارند. به عنوان مثال، برخی از لایه ها ممکن است بر روی اشکال در تصویر تمرکز کنند، در حالی که برخی دیگر ممکن است بر روی رنگ ها تمرکز کنند.
بنابراین، افزودن لایههای بیشتر میتواند به شبکههای عصبی اجازه دهد تا اطلاعات را به صورت دانهبندی بیشتری استخراج کنند – یعنی انواع بیشتری از ویژگیها را شناسایی کنند.
لایههای عمیقتر همچنین به شبکه عصبی اجازه میدهد تا درباره تعاملات انتزاعیتر بین ویژگیهای مختلف بیاموزد. به عنوان مثال، تأثیر امتیاز اعتباری بر توانایی یک فرد برای بازپرداخت وام ممکن است بر اساس دانشجو یا صاحب کسب و کار بسیار متفاوت باشد.
در یک تنظیم رگرسیون، دانشمند داده باید به صورت دستی چنین شرایط تعاملی را مشخص کند. اما همانطور که قبلاً بحث کردیم، ممکن است همیشه ندانیم که کدام عبارات تعامل مرتبط هستند، در حالی که یک شبکه عصبی عمیق می تواند این کار را برای ما انجام دهد.
مهارت آن با داده های بدون ساختار به یادگیری عمیق اجازه می دهد تا پیشرفت های عظیمی را در زمینه های بینایی کامپیوتری، تشخیص اشیا و پردازش زبان طبیعی ایجاد کند، که همگی شامل داده های بدون ساختار و طبقه بندی می شوند (به عنوان مثال، طبقه بندی اشیاء مختلف در یک تصویر به عنوان ماشین). یا یک عابر پیاده).
منابع داده آموزش یادگیری ماشین
یادگیری ماشینی با شناسایی الگوها در داده های گذشته و سپس استفاده از آنها برای پیش بینی نتایج آینده کار می کند. برای ایجاد یک مدل پیشبینی موفق، به دادههایی نیاز دارید که با نتیجه مورد علاقه مرتبط باشد. این داده ها می توانند اشکال مختلفی داشته باشند – از مقادیر عددی (دما، هزینه یک کالا و غیره) تا مقادیر زمانی (تاریخ، زمان های سپری شده) تا متن، تصاویر، ویدئو و صدا. خوشبختانه انفجار در فناوری محاسبات و حسگر همراه با اینترنت، ما را قادر ساخته است که داده ها را با نرخ های فزاینده ای ضبط و ذخیره کنیم. ترفند این است که دادههای مناسب را برای هر مشکل خاصی دریافت کنید – بیشتر کسبوکارها این را در پشتههای فناوری موجود خود ثبت میکنند، و بسیاری از این دادهها به صورت آنلاین رایگان در دسترس هستند.
داده های ساختاریافته در مقابل داده های بدون ساختار
دادههای ساختاریافته در مقابل دادههای غیرساختیافته موضوعی رایج در حوزه علم داده است، که در آن یک مجموعه داده ساختاریافته معمولاً طرحی کاملاً تعریف شده دارد و در جدولی با ردیفها و ستونها سازماندهی میشود. از سوی دیگر، دادههای بدون ساختار اغلب نامرتب و پردازش آنها دشوار است.
داده های ساختاریافته و بدون ساختار هر دو می توانند سوخت مدل های یادگیری ماشینی موفق باشند.
بیایید به جزئیات دادههای ساختاریافته در مقابل دادههای بدون ساختار، از جمله قالبهای داده، ذخیرهسازی داده، منابع داده، تجزیه و تحلیل و موارد دیگر بپردازیم.
فرمت های داده های ساختاریافته در مقابل غیرساختار
دادههای ساختاریافته قابل اندازهگیری هستند و جستجو و تجزیه و تحلیل آن آسان است و در قالبهای از پیش تعریفشده مانند CSV، Excel، XML، یا JSON ارائه میشوند، در حالی که دادههای بدون ساختار میتوانند در قالبهای متفاوتی از جمله PDF، تصاویر، صدا یا ویدیو باشند. .
داده های ساختاریافته معمولاً نتیجه یک طرح واره به خوبی تعریف شده است که اغلب توسط متخصصان انسانی ایجاد می شود. افزودن یا تغییر طرح واره داده های ساخت یافته برای افراد آسان است، اما انجام این کار با داده های بدون ساختار بسیار دشوار است.
بهطور خلاصه، دادههای ساختاریافته قابل جستجو و سازماندهی در جدول هستند و یافتن الگوها و روابط را آسان میکنند. تجزیه و تحلیل و به دست آوردن ارزش از داده های بدون ساختار، مانند استفاده از استخراج متن در فایل های PDF و به دنبال آن طبقه بندی متن، امکان پذیر است، اما این کار بسیار دشوارتر است.
منابع داده های ساخت یافته
بسیاری از ابزارهای تجاری محبوب، مانند Hubspot، Salesforce، یا Snowflake، منابع داده های ساخت یافته هستند.
مجموعه دادههای نمونه Akkio که در قالب CSV هستند نیز نمونههایی از دادههای ساختیافته هستند. به طور گسترده تر، هر فایل CSV یا Excel که به خوبی تعریف شده باشد، نمونه ای از داده های ساختاریافته است که میلیون ها نمونه از آن در سایت هایی مانند Kaggle یا Data.gov موجود است.
منابع داده بدون ساختار
به منظور مدل سازی پیش بینی، رایج ترین نوع داده های بدون ساختار متن است. این شامل فرمهای متنی، مانند فرمهای بازخورد مشتری، و همچنین ایمیلها، نظرات در سایتهای رسانههای اجتماعی، بررسی محصول یا حتی یادداشتهایی است که در طول تماسهای فروش یا جلسات کاری گرفته شدهاند.
همانطور که برجسته کردیم، داده های بدون ساختار فراتر از متن است و شامل صدا و تصویر می شود. برای مثال، بررسیهای YouTube منبع دیگری از دادههای بدون ساختار هستند. ویدئوهای یوتیوب همچنین شامل رونویسی یا گفتار به نوشتار تولید شده توسط هوش مصنوعی هستند. با توجه به این دادههای متنی، طبقهبندی متن میتواند برای استخراج این بررسیها برای بینش استفاده شود.
- ذخیره سازی داده های ساختاریافته در مقابل بدون ساختار
داده های ساختاریافته اغلب در انبارهای داده ذخیره می شوند در حالی که داده های بدون ساختار در دریاچه های داده ذخیره می شوند. یک انبار مجموعه داده های ساخت یافته را ذخیره می کند و معمولاً برای ذخیره سازی به پایگاه های داده سنتی مانند SQL Server و Oracle متکی است، در حالی که یک دریاچه داده مجموعه داده های کمتر تعریف شده ای را ذخیره می کند.
- داده های ساختار یافته در هوش مصنوعی دنیای واقعی
- داده های بدون ساختار در هوش مصنوعی دنیای واقعی
سایر مدلهای یادگیری ماشینی توسط دادههای بدون ساختار تغذیه میشوند.
تسلا از ناوگان خودروهای خودران خود برای جمع آوری اطلاعات در مورد الگوها و شرایط رانندگی استفاده می کند. این داده ها برای آموزش خودروهای خودران استفاده می شود که چگونه از برخورد اجتناب کنند و در شرایط مختلف رانندگی حرکت کنند.
نمونه دیگری در Google Photos دیده می شود. وقتی عکسی میگیرید، مدلهای یادگیری ماشینی Google تصویر را اسکن میکنند، یک نوع داده بدون ساختار، تا بفهمند در چه دستهای قرار میگیرد. سپس، کاربران میتوانند عکسهای بدون برچسب خود را بر اساس دستههایی مانند «طبیعت» یا «افراد» جستجو کنند.
تجزیه و تحلیل داده های ساخت یافته
اکثر ابزارهای تجزیه و تحلیل برای داده های ساختاریافته طراحی شده اند و تجزیه و تحلیل و به دست آوردن ارزش از داده های ساخت یافته را آسان تر از همیشه می کنند.
برای مثال، با Akkio، میتوانید دادههای ساختاریافته را برای ساخت و استقرار مدلهای هوش مصنوعی در عرض چند دقیقه بارگذاری کنید. در پسزمینه، الگوریتمهای یادگیری ماشین، دادههای جدولی را اسکن و هضم میکنند تا الگوها را بیابند و مدلی ایجاد میکنند که میتواند برای یافتن آن الگوها در دادههای جدید مستقر شود.
تجزیه و تحلیل داده های بدون ساختار
تجزیه و تحلیل داده های بدون ساختار یک کار کمتر رایج است، اما همچنان برای کسب و کارهایی که به دنبال کسب ارزش از فایل های PDF، داده های تصویری و صوتی و غیره خود هستند، بسیار مهم است.
تجزیه و تحلیل داده های بدون ساختار یک کار پیچیده است، به همین دلیل است که توسط بسیاری از مشاغل نادیده گرفته می شود.
پردازش و درک داده های بدون ساختار ممکن است دشوار باشد زیرا آشفته و در قالب های مختلف هستند. داده های بدون ساختار نیز ممکن است به جای کمی، کیفی باشند و تجزیه و تحلیل آن را حتی سخت تر کند.
یکی از موارد استفاده برای داده های بدون ساختار، تجزیه و تحلیل نظرات و نظرات در رسانه های اجتماعی، هم از طرف شرکت خود و هم از رقبا، برای اطلاع رسانی استراتژی رقابتی است.
مورد دیگر، تحلیل بازار برای یافتن فرصت های جدید است. با تجزیه و تحلیل داده های بازار بدون ساختار، مانند پست های رسانه های اجتماعی که نیازهای مشتری را ذکر می کنند، کسب و کارها می توانند فرصت هایی را برای محصولات جدید و ویژگی هایی که ممکن است نیازهای این مشتریان بالقوه را برآورده کند، کشف کنند.
داده های کمی در مقابل داده های کیفی/دسته ای
داده های کمی مجموعه ای عددی از اطلاعات است، مانند قد و وزن هر فرد در یک گروه، در کنار اندازه گروه. داده های کمی را می توان بیشتر به دو زیر دسته تقسیم کرد: داده های گسسته و پیوسته.
دادههای گسسته شامل اندازهگیریهایی نمیشود که در امتداد یک طیف هستند، بلکه در عوض به شمارش اعداد، مانند تعداد محصولات در سبد خرید مشتری، یا تعداد تراکنشهای مالی اشاره میکنند. از سوی دیگر، دادههای پیوسته به دادههایی اشاره دارد که میتوانند به طور معناداری به واحدهای کوچکتر تقسیم شوند یا در مقیاسی مانند درآمد مشتری، حقوق کارمند یا اندازه دلار یک تراکنش مالی قرار گیرند.
داده های کیفی غیر عددی هستند، مانند اینکه آیا یک معامله تقلبی است یا خیر، آیا یک بررسی دارای احساسات مثبت یا منفی است، یا اینکه آیا یک معامله فروش دارای احتمال بسته شدن بالا یا پایین است. دادههای کیفی تا حد زیادی مقولهای هستند، اما مواردی مانند متن را نیز شامل میشوند، خواه توییت، بلیط پشتیبانی مشتری یا اسناد باشد. به معنای واقعی کلمه، داده های مقوله ای صرفاً داده های مربوط به دسته ها هستند، در حالی که داده های کمی به کمیت ها مربوط می شود.
بیایید عمیقتر به تفاوتهای بین دادههای کمی و کیفی بپردازیم، با تمرکز روی دادههای طبقهای.
چگونه بفهمیم که داده های شما کمی هستند یا دسته بندی
تعیین اینکه آیا داده های شما مقوله ای یا کمی هستند می تواند دشوار باشد، اما چند مرحله وجود دارد که می توانید برای پیدا کردن آن انجام دهید.
اگر داده های شما دارای محدوده عددی مقادیر مانند درآمد، سن، اندازه تراکنش یا موارد مشابه باشد، کمی است. از سوی دیگر، اگر دستههایی مانند «بله»، «شاید» و «خیر» وجود داشته باشد، دستهبندی است.
همچنین باید نوع پاسخ هایی را که از داده های خود انتظار دارید در نظر بگیرید. آیا منتظر پاسخی هستید که طیفی از مقادیر یا فقط یک مجموعه ارزش داشته باشد؟ اگر انتظار یک مجموعه از ارزشها را دارید، مانند «تقلب» یا «نه کلاهبرداری»، آنوقت مقولهای است. اگر انتظار طیف وسیعی از مقادیر را دارید، مانند یک مقدار دلار مشخص، پس کمی است.
نمونه هایی از مدل های هوش مصنوعی که می توانید با داده های کمی بسازید
داده های کمی را می توان برای تامین انرژی طیف گسترده ای از مدل های هوش مصنوعی استفاده کرد. بیایید چند نمونه را بررسی کنیم.
پیشبینی ترافیک سایت، با توجه به دادههای ترافیک تاریخی (مثلاً اگر قرار است Google Ads را شنبه شب اجرا کنید، تعداد ترافیک مورد انتظار شما چقدر است؟)
تعیین تعداد مشتریانی که چیزی را میخرند، با توجه به فراوانی تراکنشهای تاریخی (مثلاً اگر تبلیغی را اجرا میکنید، چند نفر یک کالا را خریداری میکنند؟)
پیشبینی میزان درآمدی که با توجه به درآمد تاریخی خواهید داشت (مثلاً چند نفر روی یک تبلیغ کلیک میکنند و سپس خرید میکنند؟)
تعیین سطوح موجودی شما با توجه به ارقام فروش تاریخی (مثلاً سطح موجودی شما با توجه به ارقام فروش شما چگونه باید باشد؟)
الگوریتم های کمی یادگیری ماشین می توانند از اشکال مختلف تحلیل رگرسیون استفاده کنند، به عنوان مثال، برای یافتن رابطه بین متغیرها.
برای ارائه یک مثال ساده، اگر یک متغیر وزن بیمار و متغیر دیگر قد بیمار باشد، با اجرای تحلیل رگرسیون روی مجموعهای از بیماران، رابطه بین این متغیرها را میتوان یافت.
نمونه هایی از مدل های هوش مصنوعی که می توانید با داده های طبقه بندی شده بسازید.
داده های طبقه بندی شده همچنین می تواند طیف گسترده ای از موارد استفاده از هوش مصنوعی را تامین کند. در اینجا فقط چند نمونه آورده شده است.
طبقهبندی مشتریان بر اساس گروههای رفتاری که در آن قرار میگیرند به دستههای مختلف (مثلاً از چه نوع دستگاهی برای مرور وبسایت شما استفاده میکنند؟ آیا لباس یا کفش میخرند؟)
طبقه بندی تبلیغات خود به دسته های مختلف بر اساس اثربخشی آنها (به عنوان مثال آیا این تبلیغ نسبت به تبلیغ دیگری کلیک بیشتری جذب می کند؟)
الگوریتمهای طبقهبندی یادگیری ماشین شامل الگوریتمهای خوشهبندی برای شناسایی گروهها در یک مجموعه داده استفاده میشوند، جایی که گروهها بر اساس شباهت هستند. نامهای الگوریتم فنی شامل Naïve Bayes و K-nearest همسایگان است.
درک پیچیدگیهای این الگوریتمهای پیچیده پیشنیاز مدلسازی هوش مصنوعی بود، اما اکنون میتوانید این مدلها را در عرض چند دقیقه بسازید و بدون نیاز به تخصص فنی بسازید.
چه چیزی بهتر است: داده های کمی یا طبقه ای؟
هر نوع داده دارای مزایا و معایبی است و اینکه از کدام نوع داده استفاده شود بستگی به موقعیت دارد.
دادههای کمی ذاتاً دقیقتر از دادههای طبقهبندی هستند، زیرا جزئیات بیشتر در دادههای کمی وجود دارد. به عنوان مثال، ارتفاع “72.5 اینچ” بسیار دقیق تر از رده “قد بلند” است. درآمد «12000 دلار» بسیار دقیق تر از دسته «فقیر» است.
با استفاده از دسته ها می توان برخی از اطلاعات را از دست داد.
به عنوان مثال، یک آمریکایی با درآمد سالانه 0 دلار و دیگری با درآمد سالانه 12000 دلار هر دو در یک طبقه قانونی – فقر – حتی با تفاوت های قابل توجه در موقعیت های زندگی طبقه بندی می شوند. به طور مشابه، شخصی با دارایی خالص 30 میلیون دلار و شخصی با دارایی خالص 100 میلیارد دلار هر دو به عنوان افراد با ارزش خالص فوق العاده بالا طبقه بندی می شوند، حتی در حالی که ده ها هزار نفر در دسته قبلی وجود دارند و فقط تعداد کمی از افراد در این دسته هستند. دسته دوم
یکی از معایب دادههای کمی این است که درک و مدلسازی آن از دادههای طبقهبندی سختتر است. داده های طبقه بندی ذاتا داده ها را با کاهش تعداد نقاط داده ساده می کند.
چه چیزی رایج تر است: داده های کمی یا طبقه ای؟
هیچ پاسخ ساده ای در مورد اینکه نوع داده رایج تر است، وجود ندارد.
جمع آوری داده های طبقه بندی شده اغلب آسان تر است. به عنوان مثال، با توجه به نمایه شخصی فیس بوک، احتمالاً می توانید اطلاعاتی در مورد نژاد، جنسیت، غذای مورد علاقه، علایق، تحصیلات، حزب سیاسی و موارد دیگر دریافت کنید که همگی نمونه هایی از داده های طبقه بندی شده هستند.
از سوی دیگر، احتمالاً نمیتوانید درآمد دقیق، وزن، عادات خرج کردن یا سایر معیارهای کمی دقیق (به استثنای برخی از موارد استثنایی مانند سن) را بدانید.
با این حال، وضعیت کاملاً متفاوت است، زیرا فیس بوک حجم زیادی از داده ها را در مورد هر یک از کاربران خود جمع آوری می کند که بیشتر آنها کمی هستند، مانند مدت زمان صرف شده برای مشاهده یک پست، تعداد پست های مشاهده شده، تعداد. تعداد بازدید پروفایل، تعداد کلیک روی لینک، تعداد برنامه باز شده و غیره.
در نهایت، ما هر روز، تقریباً با هر اقدامی که انجام میدهیم، مقادیر زیادی از هر دو نوع داده را ایجاد میکنیم. وقتی گوشی هوشمند جدیدی را برمی دارید، حسگرها با ردیابی موقعیت مکانی دقیق گوشی شما در هر نقطه از زمان، که نمونه ای از داده های کمی است، تشخیص می دهند که آن را گرفته اند. سپس، همانطور که تشخیص می دهد تلفن شما برداشته شده است، ممکن است متغیری مانند “وضعیت” را به جای “غیرفعال” به “فعال” تغییر دهد و باعث روشن شدن صفحه قفل گوشی شما شود..
سری زمانی
دادههای سری زمانی نوعی داده است که رویدادهایی را که در طول زمان اتفاق میافتند ثبت میکند، که به ویژه در پیشبینی رویدادهای آینده مفید است.
برای ارائه یک مثال بسیار ساده، در اینجا مجموعه داده سری زمانی با سه نقطه داده آورده شده است: در سال 1975، دمای سطح جهانی زمین 0.0 درجه سانتیگراد غیرعادی بود، در سال 1995 + 0.5 درجه سانتیگراد بالاتر از حد معمول بود، و در سال 2015 این دمای 0.9 + بود. درجه سانتیگراد بالاتر از حد معمول است.
یکی از اصول کلیدی دادههای سری زمانی این است که وقتی چیزی اتفاق میافتد به همان اندازه مهم است که چه اتفاقی میافتد. به عنوان مثال، در بازاریابی، مدت زمانی که مشتری طی می کند تا مراحل قیف بازاریابی را طی کند، پیش بینی کننده مهم درآمد است.
برنامه های کاربردی رایج
یکی از مهمترین کاربردهای داده های سری زمانی، پیش بینی است. این به این دلیل است که گذشته بهترین پیش بینی کننده آینده است. بیایید برخی از کاربردهای رایج دادههای سری زمانی، از جمله پیشبینی و موارد دیگر را بررسی کنیم.
سفر بازاریابی
بازاریابی یک سفر است و سفر مشتری از طریق قیف بازاریابی می تواند غیرقابل پیش بینی به نظر برسد.
با این حال، راههای زیادی برای پیشبینی سفر مشتری و رسیدن به آنها در زمان مناسب وجود دارد تا جذب مشتری و نرخ تبدیل افزایش یابد. با درک سفرهای مشتری، بازاریابان همچنین می توانند یک تجربه محتوای مرتبط تر و قانع کننده تر برای هر مرحله از سفر ایجاد کنند.
به عنوان مثال، اگر در حال اجرای یک کمپین بازاریابی در اینستاگرام هستید و میخواهید بدانید تبلیغات شما چند کلیک دریافت میکند، میتوانید کلیکها را بر اساس دادههای تاریخی پیشبینی کنید.
برای مثال دیگر، پیشبینی سریهای زمانی میتواند برای پیشبینی زمان خرید بعدی مشتریان استفاده شود. این به شرکت ها اجازه می دهد تا در مورد زمان عرضه محصولات جدید و زمان ارسال ایمیل یا سایر پیام های مصرف کننده تصمیم گیری کنند.
نرخ اجرا درآمد
نرخ اجرا درآمد پیش بینی درآمد بر اساس آنچه در گذشته اتفاق افتاده است.
این یک معیار مهم برای شرکت ها است زیرا به آنها کمک می کند تا برای نیازهای درآمدی آینده برنامه ریزی کنند. نرخ اجرای درآمد یک معیار سالانه است که به طور سنتی با ضرب متوسط درآمد در ماه در 12 یا میانگین درآمد در هر سه ماه در 4 محاسبه می شود. این یک تخمین تقریبی از میزان درآمد شرکت در سال را نشان می دهد.
با این حال، این یک روش بسیار خشن برای تخمین درآمد است که می تواند بسیار نادرست باشد. به عنوان مثال، کسبوکارهایی مانند مراکز تناسب اندام معمولاً در ژانویه به دلیل تصمیمگیریهای سال نو عملکرد بهتری دارند، بنابراین نمیتوانند درآمد را با روشهای سنتی بهطور دقیق پیشبینی کنند. وضعیت برعکس برای یک شرکت محوطه سازی صادق است، که احتمالاً در ژانویه تجارت زیادی نخواهد داشت.
تعدادی از متغیرهای دیگر نیز بر درآمد تأثیر میگذارند، از بودجههای پویا گرفته تا رقبای جدید یا نوآوری محصول جدید. محاسبات سنتی که صرفاً مبتنی بر چند برابر شدن درآمد تاریخی است، همه این عوامل دیگر را نادیده می گیرد.
با استفاده از پیشبینی Akkio، میتوانید نرخ درآمد را بر اساس هر تعداد متغیر پیچیده در دادههای خود بهطور دقیق پیشبینی کنید.
ارزش سهام یا کریپتو
پیشبینی قیمت سهام و کریپتو بسیار دشوار است، بهویژه با توجه به مشکلات فنی ساخت دستی و استقرار مدلهای پیشبینی.
گفته می شود، برای سرمایه گذارانی که علاقه مند به پیش بینی دارایی ها هستند، داده های سری زمانی و یادگیری ماشینی ضروری است. با Akkio، می توانید داده های سری زمانی سهام و دارایی های رمزنگاری شده را برای پیش بینی قیمت ها متصل کنید.
مهم است که به یاد داشته باشید که سهام و رمزارز انواع مختلفی از سرمایه گذاری هستند، زیرا بازارهای کریپتو بسیار کوچکتر و بی ثبات تر هستند. سرمایه گذاران باید هنگام سرمایه گذاری در سهام و ارزهای دیجیتال مراقب احساسات خود باشند.
سلامت دستگاه
سازندگان از هوش مصنوعی سری زمانی برای نگهداری پیش بینی و نظارت بر سلامت تجهیزات استفاده می کنند. سیستم های هوش مصنوعی می توانند تشخیص دهند که چه زمانی باید تغییراتی برای بهبود کارایی ایجاد شود. آنها همچنین می توانند پیش بینی کنند که چه زمانی تجهیزات خراب می شود و قبل از وقوع آن هشدار ارسال می کنند.
این فناوریها با عدم صرف هزینه برای تعمیرات غیرمنتظره یا تعویض فوری ماشینآلات در زمانی که دیگر کار نمیکنند، در هزینه تولیدکنندگان صرفهجویی میکنند.
مجموعه داده های سری زمانی
برای افراد غیر متخصص، یافتن مجموعه داده های سری زمانی با کیفیت بالا یک چالش است. خوشبختانه، تعداد زیادی از منابع مجموعه زمانی رایگان و با کیفیت بالا به صورت آنلاین موجود است.
بیایید چند منبع داده سری زمانی را بررسی کنیم.
مخزن سری زمانی UCI
مخزن UCI دارای ۴۸ مجموعه داده سری زمانی است که از کیفیت هوا گرفته تا دادههای پیشبینی فروش را شامل میشود.
بیشتر دادهها در قالب CSV ارائه میشوند، بنابراین خواندن آن با ابزارهایی مانند Akkio آسان است، بدون نیاز به پیش پردازش دستی. فقط یک مجموعه داده را متصل کنید، و شما آماده هستید!
شاخص های توسعه جهانی بانک جهانی
بانک جهانی بانک اطلاعات گستردهای با ۷۹ پایگاه داده برای ۲۶۴ کشور با دادههای مربوط به سال ۱۹۶۰ ارائه میکند.
برای مثال، پایگاه داده شاخصهای توسعه جهانی، شامل بیش از 1440 ستون داده برای انتخاب میشود، از شاخصهای سطح بالا مانند «درصد دسترسی به برق» تا شاخصهای بسیار تخصصی مانند «جمعیت روستایی ساکن در مناطقی که ارتفاع آن زیر 5 متر است». پایگاه داده آمار آموزش شامل تقریبا 4000 ستون داده است.
پاسخ آسانی برای تعداد مجموعه داده های سری زمانی ارائه شده وجود ندارد، اما اگر هر مجموعه داده سری زمانی بالقوه را به عنوان یک مشکل تک متغیره در نظر بگیرید، میلیون ها مجموعه داده تنها از این منبع وجود دارد (79 پایگاه داده در 264 کشور با میانگین 2000 ستون های داده).
ملاحظات ویژه برای داده های سری زمانی
دادههای سری زمانی به دلایل مختلفی میتوانند یک نوع داده بسیار دشوار برای کار کردن باشند. ما برخی از ملاحظات ویژه را که باید هنگام کار با داده های سری زمانی در نظر داشته باشید، برجسته کرده ایم.
دادههای سری زمانی متوالی هستند، اما بسیاری از الگوریتمها برای پیشبینی آینده اینطور نیستند.
در مجموعه داده های سری زمانی، جنبه زمانی بسیار مهم است، اما بسیاری از الگوریتم های یادگیری ماشین از این جنبه زمانی استفاده نمی کنند، که مدل های گمراه کننده ای را ایجاد می کند که در واقع آینده را پیش بینی نمی کنند.
به عنوان مثال، یک مدل «راهپیمایی تصادفی» یک فرآیند تصادفی است، به این معنی که پیشبینی دقیق نتایج آینده از دادههای تاریخی برای آن امکانپذیر نیست.
برای مثال دیگر، مدلهای رگرسیون پایه، همبستگی زمانی را در دادههای مشاهدهشده نادیده میگیرند و مقدار بعدی سریهای زمانی را صرفاً بر اساس روشهای رگرسیون خطی پیشبینی میکنند.
علاوه بر این، بسیاری از مدلهای سری زمانی با یافتن همبستگیهای کاذب، به جای متغیرهای علّی، به راحتی میتوانند به دادهها «اضافه شوند».
برای مثال، رابطه مثبتی بین فروش بستنی و قتل وجود دارد، اما بدیهی است که نه به این دلیل که خوردن بستنی باعث میشود که بخواهید مردم را بکشید. این همان چیزی است که به عنوان “همبستگی جعلی” شناخته می شود.
در مورد بستنی فروشی و قتل، اتفاقی که می افتد این است که فروش بستنی در تابستان افزایش می یابد، یعنی زمانی که افراد بیشتری به بیرون از خانه می روند و باعث افزایش طبیعی جرم و جنایت می شود (وقتی همه در زمستان در داخل بسته می شوند، جرایم کمتری انجام می شود. در مقابل، مثلاً، زمانی که یک رویداد ورزشی در تابستان با 50000 شرکت کننده در یک استادیوم وجود دارد).
تولید مدلی که آینده را از روی داده های سری زمانی پیش بینی می کند، کار بسیار زیادی است.
مدلسازی دادههای سری زمانی یک تلاش فشرده است که نیاز به پیش پردازش، تمیز کردن دادهها، آزمایشهای ثابت، روشهای ثابتسازی مانند تغییر روند یا تفاوت، یافتن پارامترهای بهینه و موارد دیگر دارد.
انجام این کار به صورت دستی به تخصص فنی بالایی نیاز دارد، البته به تعهد زمانی زیاد نیز اشاره نمی کنیم. با Akkio، این فرآیندهای پیچیده در back-end خودکار می شوند، بنابراین می توانید داده ها را بدون زحمت پیش بینی کنید.
دادههای سری زمانی اغلب در مورد پیشبینی آینده دقیق نیستند، زیرا بسیاری از چیزهایی که در گذشته اتفاق افتاده است دیگر به آینده مرتبط نیستند.
اگر تا به حال به سرمایه گذاری فکر کرده اید، احتمالاً یک سلب مسئولیت مالی در امتداد این موارد خوانده اید: “عملکرد گذشته تضمینی برای نتایج آینده نیست.”
این در واقع یک الزام قانونی برای شرکت های مدیریت دارایی است که چنین سلب مسئولیتی را ارائه کنند، زیرا، خوب، واقعاً راهی برای دانستن آینده وجود ندارد. بهترین کاری که می توانیم انجام دهیم این است که احتمالات را به مقادیر خاصی اختصاص دهیم.
در واقع، حتی ایجاد احتمالات دقیق نیز بسیار چالش برانگیز است، زیرا جهان دائما در حال تغییر است. پیشبینی موارد COVID-19 نمونهای عالی از چالشهای پیشبینی سریهای زمانی است، زیرا تقریباً همه پیشبینیها شکست خوردند.
حتی در حال حاضر، با توجه به اینکه با توجه به واکسنهای جدید، سویههای جدید و مقررات در حال تغییر پیرامون سفر، فاصلهگذاری اجتماعی، قرنطینه و غیره، بسیاری از دادههای گذشته دیگر برای آینده مرتبط نیستند، پیشبینی دقیق بسیار دشوار است.
مهندسی ویژگی برای داده های سری زمانی
مهندسی ویژگی فرآیند ایجاد ویژگی های جدید از داده های موجود است.
یک چالش با داده های سری زمانی این است که اغلب ثابت نیستند. ایستایی به این معنی است که یک سری زمانی دنباله ای از مشاهدات یک متغیر است که در زمان های مساوی با فاصله گرفته شده است. اگر مشاهدات در زمان به یک اندازه فاصله داشته باشند و هیچ روند یا فصلی نداشته باشند، ثابت است.
ایجاد دادههای ثابت شکلی از مهندسی ویژگی است و دو روش رایج برای تبدیل سریهای زمانی به دادههای ثابت، تفاوت و تبدیل است.
گفته میشود، با ابزارهای هوش مصنوعی بدون کد مانند Akkio، میتوانید مدلهای سری زمانی را بدون نیاز به مهندسی ویژگی دستی بسازید و استقرار دهید، زیرا این کار به طور خودکار پس از اتصال مجموعه داده انجام میشود.
برای آموزش یک مدل ML به چه مقدار داده نیاز دارم؟
داده ها سوختی هستند که باعث می شود یادگیری ماشین تیک بخورد. در بیشتر موارد، هرچه دادههای بیشتری داشته باشید، مدل شما دقیقتر خواهد بود، اما موارد زیادی وجود دارد که میتوانید با کمترین هزینه از پس آن برآیید.
مدل های یادگیری ماشینی ماشین های تطبیق الگو هستند. آنها فقط می توانند الگوهایی را که قبلاً دیده شده اند، ضبط و پیش بینی کنند. این یکی از موارد مهم در یادگیری ماشینی است. اگر میخواهید پیشبینی کنید که با دادههای جدید چه اتفاقی میافتد، مدل باید قبلاً دادههای مشابهی را دیده باشد.
همچنین مهم است که توجه داشته باشید که هیچ قانون طلایی برای مقدار داده مورد نیاز شما وجود ندارد. به عنوان مثال، در حالی که مجموعه داده آزمایشی امتیازدهی سرنخ Akkio دارای بیش از 40000 ردیف داده است، مجموعه داده آزمایشی طبقهبندی متن تنها دارای 1000 ردیف داده است و هر دو تقریباً 90 درصد دقت دارند. در همین حال، مجموعه داده نمایشی تقلب کارت اعتباری نزدیک به 300000 ردیف داده دارد!
بهتر است فرآیند مدلسازی مجموعه دادههای خود را بررسی کنید و ببینید برای به دست آوردن دقت بالا چه چیزی لازم است.
آیا داده های خیلی کمی دارید؟
مدلهای یادگیری ماشینی دقیق را میتوان با چند صد ردیف داده ایجاد کرد. اگر واقعاً دادههای بسیار کمی دارید، مثلاً کمتر از چند صد ردیف، میتوانید چند چیز را امتحان کنید.
یکی افزایش داده است: فرآیندی که در آن داده ها با افزودن نمونه های جعلی داده تولید می شوند. همچنین می توانید در سایر مجموعه داده ها، اعم از داخلی یا خارجی، در ستون های مشترک ادغام شوید تا اندازه کلی مجموعه داده را افزایش دهید.
برای مثال، فرض کنید در حال ساخت مدلی برای طبقهبندی بلیطهای پشتیبانی مشتری بر اساس فوریت هستید. اگر به دادههای بیشتری نیاز دارید، باید مطمئن شوید که خط لولهای دارید که این دادهها را برای شما تولید میکند. در چنین حالتی، تیم های پشتیبانی شما باید فوریت بلیط های دریافتی را برچسب گذاری کنند، بنابراین می توانید بعداً این داده ها را برای تقویت مدل یادگیری ماشین خود صادر کنید.
بسته به مورد استفاده، حتی میتوانید به پلتفرمهای جمعسپاری مانند Amazon Mechanical Turk روی بیاورید. این پلتفرمها به شما امکان میدهند افرادی را از سراسر جهان استخدام کنید تا کارهای کوچکی را با قیمتهای پایین برای شما انجام دهند، مانند جمعآوری و برچسبگذاری دادهها. اگر یک شرکت کوچک با منابع محدود هستید، ممکن است نخواهید این کار را انجام دهید، اما اگر شرکت بزرگی هستید و به سرعت داده های بیشتری می خواهید، این ممکن است گزینه خوبی برای شما باشد.
روش دیگر حذف دادهها از اینترنت است، که باز هم به موارد استفاده وابسته است، اما با توجه به ماهیت باز بودن بسیاری از دادههای اینترنتی، مانند پستهای رسانههای اجتماعی، به طور بالقوه راهی آسان برای افزایش اندازه مجموعه داده شما است.
آیا داده های زیادی دارید؟
مواردی وجود دارد که به نظر می رسد داده های زیادی دارید. اگر مجموعه داده شما خیلی بزرگ باشد، کاوش و درک آنچه که داده ها به شما می گویند دشوار می شود. این مورد به ویژه در مورد داده های بزرگ به ترتیب چندین گیگابایت یا حتی ترابایت است که با ابزارهای معمولی مانند اکسل یا حتی کد معمولی پایتون پاندا قابل تجزیه و تحلیل نیستند.
با توجه به اینکه امکان ساخت مدلهای یادگیری ماشینی با کیفیت بالا با مجموعه دادههای بسیار کوچکتر وجود دارد، این مشکل را میتوان با نمونهگیری از مجموعه داده بزرگتر و استفاده از نمونه مشتقشده و کوچکتر برای ساخت و استقرار مدلها حل کرد.
مدلهای یادگیری ماشینی دقیق را میتوان با چند صد ردیف داده ایجاد کرد. اگر واقعاً دادههای بسیار کمی دارید، مثلاً کمتر از چند صد ردیف، میتوانید چند چیز را امتحان کنید.
یکی افزایش داده است: فرآیندی که در آن داده ها با افزودن نمونه های جعلی داده تولید می شوند. همچنین می توانید در سایر مجموعه داده ها، اعم از داخلی یا خارجی، در ستون های مشترک ادغام شوید تا اندازه کلی مجموعه داده را افزایش دهید.
برای مثال، فرض کنید در حال ساخت مدلی برای طبقهبندی بلیطهای پشتیبانی مشتری بر اساس فوریت هستید. اگر به دادههای بیشتری نیاز دارید، باید مطمئن شوید که خط لولهای دارید که این دادهها را برای شما تولید میکند. در چنین حالتی، تیم های پشتیبانی شما باید فوریت بلیط های دریافتی را برچسب گذاری کنند، بنابراین می توانید بعداً این داده ها را برای تقویت مدل یادگیری ماشین خود صادر کنید.
بسته به مورد استفاده، حتی میتوانید به پلتفرمهای جمعسپاری مانند Amazon Mechanical Turk روی بیاورید. این پلتفرمها به شما امکان میدهند افرادی را از سراسر جهان استخدام کنید تا کارهای کوچکی را با قیمتهای پایین برای شما انجام دهند، مانند جمعآوری و برچسبگذاری دادهها. اگر یک شرکت کوچک با منابع محدود هستید، ممکن است نخواهید این کار را انجام دهید، اما اگر شرکت بزرگی هستید و به سرعت داده های بیشتری می خواهید، این ممکن است گزینه خوبی برای شما باشد.
روش دیگر حذف دادهها از اینترنت است، که باز هم به موارد استفاده وابسته است، اما با توجه به ماهیت باز بودن بسیاری از دادههای اینترنتی، مانند پستهای رسانههای اجتماعی، به طور بالقوه راهی آسان برای افزایش اندازه کلی مجموعه داده است.
مدل های ML در هر اندازه ای
یک نمونه خوب از یک مدل عظیم هوش مصنوعی، آخرین مدل زبان گوگل است که اندازه باورنکردنی 1.6 تریلیون پارامتر دارد – برای ما بسیار بزرگ است که عملاً آن را درک کنیم، اگرچه برای مقایسه، فقط 86 میلیارد نورون در مغز انسان وجود دارد.
در عین حال، می توان مدل های یادگیری ماشینی ساخت که حدود 10 مرتبه کوچکتر از مدل زبان گوگل هستند.
به عنوان مثال، پرسپترون یک طبقه بندی است که در دهه 1950 ساخته شد. این شبکههای عصبی تک لایه با اختصاص دادن ورودیها به خروجیهای مختلف آموزش داده میشوند و شبکه وزن خود را تا زمانی که بتواند خروجی ورودیهای جدید را به درستی پیشبینی کند، تنظیم میکند. پرسپترون به دلیل کمبود حافظه و عدم توانایی در برون یابی روابط بین نقاط داده ای که ممکن است ندیده باشد محدود شده است، اما در هسته خود، می تواند اساس یک مدل عملکردی با تنها چند پارامتر باشد.
کمیت همه چیز نیست
مهم است که به یاد داشته باشید که کمیت همه چیز در مورد داده ها نیست. حتی اگر داده های زیادی داشته باشید، ممکن است مدل شما به خوبی کار نکند. برای داشتن مدل های باکیفیت، به داده هایی با کیفیت بالا نیاز دارید. این به این معنی است که داده های شما باید تمیز و کار با آنها آسان باشد تا بتوان از آنها به طور موثر استفاده کرد.
به عبارت دیگر، بهتر است یک مجموعه داده کوچک و با کیفیت بالا داشته باشید که نشاندهنده مشکلی باشد که میخواهید حل کنید، تا یک مجموعه داده بزرگ و عمومی که مملو از مشکلات کیفیت باشد.
پس از همه، همه داده ها ارزشمند نیستند. همانطور که نیت سیلور، بنیانگذار FiveThirtyEight، میگوید: «هر روز، سه بار در ثانیه، معادل مقدار دادهای که کتابخانه کنگره در کل مجموعه چاپی خود دارد، تولید میکنیم، درست است؟ اما بیشتر آن مانند ویدیوهای گربه در یوتیوب یا افراد 13 ساله است که در مورد فیلم بعدی گرگ و میش پیام های متنی رد و بدل می کنند.
آزمایش کنید تا متوجه شوید به چه مقدار داده نیاز دارید
یادگیری ماشینی آسانتر و سریعتر میشود. نیازی به هدر دادن زمان زیادی برای آماده سازی نیست، زیرا یک مجموعه داده عظیم پیش نیاز نیست. همانطور که آدام ساویج می گوید: “در روح علم، واقعا چیزی به نام “آزمایش ناموفق” وجود ندارد.” به سادگی آزمایش کنید و ببینید به چه مقدار داده نیاز دارید.
در چند سال اخیر، یادگیری ماشین و ابزارهای هوش مصنوعی سادهتر و سریعتر شدهاند. روزهای انتظار هفته ها یا ماه ها برای ساخت و استقرار مدل ها به پایان رسیده است. با Akkio، میتوانید یک مدل را در کمتر از 10 ثانیه بسازید، به این معنی که فرآیند تعیین میزان دادهای که واقعاً برای یک مدل مؤثر نیاز دارید، سریع و بدون زحمت است.
با یادگیری ماشین سنتی، شما معمولاً به یک مجموعه داده بزرگ نیاز دارید تا داده های آموزشی کافی به دست آورید. اما با Akkio، می توان مدل های قانع کننده ای با حداقل 100 یا 1000 نمونه ایجاد کرد. همانطور که بررسی کردیم، اگر متوجه شدید که با مجموعه دادههای کوچک نتایج عالی کسب نمیکنید، همیشه میتوانید دادههای جدید، تقویت دادهها، پلتفرمهای جمعسپاری یا صرفاً به منابع داده آنلاین روی آورید.
آماده سازی داده ها برای یادگیری ماشینی
آمادهسازی دادههای شما برای آموزش یک مدل یادگیری ماشینی میتواند از اتصال ساده پلتفرمهای فناوری عملیات تجاری موجود (Salesforce، Marketo، و Hubspot، و غیره) و فروشگاههای داده (Snowflake، Google Big Query و غیره) تا بهداشت دادههای تجاری گسترده باشد. برنامههایی که ماهها طول میکشد، اما دادههای تمیزی را برای عملکرد بهینه به دست میآورند. همچنین باید مجموعه داده مورد استفاده برای آموزش را محدود کنید تا زمانی که میخواهید یک نتیجه کلیدی را پیشبینی کنید، اطلاعات در دسترس شما باشد. ما Akkio را طوری طراحی کردهایم که با دادههای نامرتب و همچنین تمیز کار کند – و معتقدیم که 90٪ از ارزش یادگیری ماشینی را با کسری از هزینه یک طرح بهداشتی دادهها به دست میآوریم. برای کسب اطلاعات بیشتر درباره آمادهسازی دادههای خود برای یادگیری ماشینی، اینجا را کلیک کنید.
افزایش داده برای یادگیری ماشین
عملکرد یک مدل یادگیری ماشین در درجه اول به دقت پیشبینی مجموعه داده آموزشی آن با توجه به نتیجه مورد علاقه بستگی دارد. اگر بتوانید همه چیز را در مورد یک سیستم بدانید (به کنار فیزیک کوانتومی)، میتوانید وضعیت آینده آن را کاملاً پیشبینی کنید. در واقع، بیشتر مجموعههای داده حاوی زیرمجموعه کوچکی از اطلاعات در مورد یک سیستم هستند – اما این اغلب برای ساخت یک مدل ارزشمند ML کافی است. گفته می شود، افزودن داده های اضافی اغلب می تواند به بهبود عملکرد پیش بینی کمک کند. به این کار افزایش داده می گویند. برای کسب اطلاعات بیشتر درباره افزایش داده برای یادگیری ماشین، اینجا را کلیک کنید.
تعصب در یادگیری ماشینی: چیست و چگونه می توان از آن اجتناب کرد؟
یکی از موارد بسیار مهمی که هنگام استفاده از یادگیری ماشین باید از آن آگاه بود این است که سوگیری در مجموعه داده مورد استفاده برای آموزش مدل در تصمیم گیری خود مدل منعکس می شود. گاهی اوقات این سوگیری ها در داده های شما آشکار نیستند – برای مثال کد پستی یا پستی را در نظر بگیرید. اطلاعات مکان اطلاعات زیادی را رمزگذاری می کند که ممکن است در نگاه اول واضح نباشد – همه چیز از آب و هوا گرفته تا تراکم جمعیت گرفته تا درآمد، مسکن و اطلاعات جمعیتی مانند سن و قومیت. این الگوها میتوانند مفید باشند، اما در صورت استفاده از مدلها به روشهایی که نتایج تبعیضآمیز ناخواسته (هم از نظر اخلاقی و هم از نظر قانونی) را تقویت میکنند، پتانسیل مضر بودن را نیز دارند. اینجا را کلیک کنید تا درباره سوگیری در یادگیری ماشینی و نحوه به حداقل رساندن آن بیشتر بدانید.
از موارد یادگیری ماشین استفاده کنید
یادگیری ماشینی زیرمجموعهای از هوش مصنوعی است که بر سیستمهایی متمرکز است که میتوانند از دادهها یاد بگیرند.
در حالی که برخی از کاربردهای برتر یادگیری ماشینی را در تعدادی از صنایع بررسی خواهیم کرد، دنیای دانشگاهی نیز از هوش مصنوعی استفاده میکند، تا حد زیادی برای تحقیقات در زمینههایی مانند زیستشناسی، شیمی، و علم مواد.
انرژی
انرژی تجدید پذیر
انرژی های تجدیدپذیر یکی از سریع ترین منابع تولید برق در سراسر جهان است. در سال 2020، 80 درصد از ظرفیت جدید برق در سطح جهان را به خود اختصاص داد.
هوش مصنوعی برای پذیرش موفقیت آمیز حیاتی است. هوش مصنوعی میتواند نیازهای عرضه و تقاضای برق را در زمان واقعی متعادل کند، استفاده و ذخیرهسازی انرژی را برای کاهش نرخها بهینه کند و به ادغام منابع جدید و پاک در زیرساختهای موجود کمک کند. هوش مصنوعی همچنین می تواند با یادگیری از رویدادهای گذشته، قطع برق در آینده را پیش بینی کرده و از آن جلوگیری کند.
به عنوان مثال، هنگامی که یک شبکه تحت فشار تقاضا قرار می گیرد، هوش مصنوعی می تواند مسیر جریان انرژی و مصرف برق آن شبکه را پیش بینی کند، سپس برای جلوگیری از قطع برق اقدام کند. هوش مصنوعی همچنین می تواند زمان وقوع قطع برق در آینده را پیش بینی کند، بنابراین شرکت های برق می توانند اقدامات پیشگیرانه ای را برای به حداقل رساندن اثرات قطعی انجام دهند.
علاوه بر این، هوش مصنوعی حتی می تواند به انرژی باد کمک کند. قدرت باد همیشه وجود دارد، اما مهار آن آسان نیست. آسیابهای بادی برای قرنها برای جذب نیروی باد مورد استفاده قرار میگرفتند، اما این فرآیند دشوار و پرهزینه است.
اما اکنون هوش مصنوعی می تواند بازی را تغییر دهد. هوش مصنوعی میتواند محاسبه کند که توربینهای بادی چگونه باید بچرخند به طوری که کمترین تعداد توربینهای ممکن در سایه باد دیگری قرار بگیرند. با استفاده از داده های جمع آوری شده از زمین، ارتفاع و اندازه توربین ها و داده های هواشناسی، هوش مصنوعی می تواند نحوه چرخش توربین های بادی را برای مهار باد تعیین کند.
بیمه
قیمت گذاری بیمه
صنعت بیمه به شدت رقابتی است. واقعیت ساده این است که اگر به طور مداوم سودآور نباشید، از بازار رانده خواهید شد. برای حفظ سودآوری، شرکت های بیمه باید بتوانند به طور دقیق افراد پرخطر و پرهزینه را پیش بینی کنند.
در واقع، داده ها نشان می دهد که 70 درصد از شرکت های بیمه جدید آمریکای شمالی ظرف 10 سال شکست می خورند. این وضعیت موجود است، زیرا شرکت های بیمه اغلب نمی توانند به طور دقیق برنامه های خود را قیمت گذاری کنند، که منجر به زیان های عظیم می شود.
نشان داده شده است که هوش مصنوعی در پیشبینی هزینههای ادعاهای آتی بسیار دقیق است. این دقت به شما این امکان را می دهد که ریسک بیمه کردن یک فرد را بر اساس سابقه مطالبات گذشته آنها ارزیابی کنید و از این اطلاعات برای قیمت گذاری صحیح حق بیمه خود استفاده کنید.
این بسیار مهم است زیرا به شما این امکان را می دهد که در یک صنعت پر خطر که در آن همیشه در معرض خطر حذف شدن از تجارت با انتخاب نامناسب هستید، سودآور بمانید.
با Akkio، مدلسازی هزینه مبتنی بر هوش مصنوعی را میتوان با کلیک انجام داد، و به بیمهگران این امکان را میدهد تا رقبای خود را که با استفاده از مدلهای هزینه سنتی، پرزحمت و نادرست گیر کردهاند، پیشی بگیرند. این مدل سازی هزینه یکی از بزرگترین مشکلات بیمه گذاران امروزی را حل می کند: انتخاب چه کسی و با چه نرخی.
مدل سازی توسعه دعوی
در صنعت بیمه، همه چیز در مورد مدیریت ریسک است. و هنگامی که در مورد ریسک پیش بینی می کنید، می خواهید آن را به درستی انجام دهید. در گذشته، صنعت بر تکنیکهای مدلسازی قدیمی تکیه میکرد که اغلب منجر به ادعای قیمتگذاری کمتر یا بیش از حد میشد. که منجر به حق بیمه بالاتر برای مصرف کنندگان و انبوهی از مشکلات دیگر شد.
اما هوش مصنوعی این مشکل را حل می کند. با استفاده از این تکنیکهای جدید یادگیری ماشین، میتوان بهطور دقیق هزینه ادعا را پیشبینی کرد و مدلهای پیشبینی دقیق را در عرض چند دقیقه ساخت. نه تنها این، بلکه بیمهگران حتی میتوانند مدلهایی را برای پیشبینی چگونگی تغییر هزینههای خسارت بسازند و تغییرات تخمین موردی را محاسبه کنند.
این بدان معناست که شرکت های بیمه می توانند بیمه نامه های خود را با دقت بیشتری قیمت گذاری کنند و حق بیمه کمتری را برای مصرف کنندگان ارائه دهند که منجر به کاهش هزینه های پوشش برای همه می شود. همچنین به بیمهگران کمک میکند تا رقابتیتر باشند و مشتریان بیشتری را جذب کنند، که به ویژه از آنجایی که صنعت با رقابت سختی مواجه است، اهمیت دارد.
پلتفرم Akkio با این امکان را به کاربران میدهد تا مدلهایی را بر اساس دادههای خود ایجاد کنند و سپس آنها را در هر تعداد محیطی تنها با چند کلیک مستقر کنند. این امر نیاز به کار توسعه سفارشی پرهزینه و وقت گیر را کاهش می دهد و به طور کلی به هزینه های کمتری برای شرکت تبدیل می شود.
همچنین بیمهگران را قادر میسازد تا سریعتر به یک بازار بیمه در حال تغییر پاسخ دهند، که یک مزیت مهم در برابر رقبای که هنوز بر تکنیکهای قدیمی مانند مدلسازی رگرسیون در اکسل متکی هستند، فراهم میکند. نتیجه یک تجربه مشتری بهبود یافته است که به حجم فروش بالاتر و سهامداران راضی تر تبدیل می شود.
مدلسازی اتوماسیون پرداخت دعوی
مطالبات یک هزینه عمده برای شرکت های بیمه و یک فرآیند خسته کننده برای بیمه شدگان است. در عین حال، ادعاهای بیمه بسیار رایج است، زیرا در سن 34 سالگی، هر فردی که از 16 سالگی رانندگی می کند، احتمالا حداقل یک ادعای بیمه خودرو را ارائه کرده است.
ناکارآمدی در رسیدگی به دعاوی برای هر دو طرف بد است: مشتری وقت خود را تلف میکند و شرکت بیمه بیش از آنچه میتوانست برای تسویه خسارت هزینه کند، برای رسیدگی هزینه میکند. یادگیری ماشینی بدون کد Akkio می تواند مدل سازی کند که بهترین زمان پرداخت خودکار مطالبات است، به طوری که می توانید زمان انتظار برای مشتریان را به حداقل برسانید و بازگشت سرمایه را برای کسب و کار خود به حداکثر برسانید.
پیشبینی اینکه مشتری چه زمانی ادعا میکند کار سادهای نیست. مشخصات ریسک شما در طول زمان تغییر می کند و همچنین رقابت پذیری بازار شما نیز تغییر می کند. با توجه به دادههای تاریخی مناسب، مدلهای یادگیری ماشینی Akkio همه این موارد را در نظر میگیرند و یافتن راهحل بهینه برای نیازهای خاص شما را آسان میکنند.
به سادگی داده های خود را آپلود کنید و به Akkio اجازه دهید کارهای سنگین را انجام دهد و به شما زمان بیشتری برای تمرکز بر آنچه واقعاً مهم است: اداره تجارت خود می دهد.
مدل سازی تبدیل بیمه
شرکت های بیمه همیشه به دنبال راه های جدیدی برای جذب مشتریان جدید هستند و باید تلاش های بازاریابی خود را برای کمک به رشد آنها بهینه کنند.
یکی از مشکلات کلیدی که بسیاری از شرکت های بیمه با آن دست و پنجه نرم می کنند این است که چگونه تصمیمات دقیق قیمت گذاری را اتخاذ کنند. با توجه به اینکه بیمه با استناد به بیمه نامه فروخته می شود، برآورد دقیق نرخ تبدیل از مظنه به بیمه نامه ضروری است. Akkio به شما امکان می دهد داده های تاریخی را جمع آوری کنید، در مورد احتمال تبدیل تخمین بزنید و سپس از آن پیش بینی ها برای هدایت تصمیمات قیمت گذاری خود استفاده کنید.
مدل سازی دقیق تبدیل بیمه کلیدی است زیرا عامل تعیین کننده مهمی در سودآوری شرکت بیمه است.
یکی از مزایای کلیدی رویکرد مبتنی بر هوش مصنوعی این است که به شرکتهای بیمه اجازه میدهد تا قیمتها را برای بخشهای مشتریان بدون ایجاد و آزمایش دستی طیف گستردهای از انواع قیمتگذاری تنظیم کنند. این تضمین می کند که دلارهای بازاریابی به طور مؤثر و کارآمد در بخش هایی که بیشترین شانس برای تبدیل وجود دارد، خرج می شود.
مدل سازی ادعای تقلبی (Fraudulent Claim Modeling )
با توجه به آمار FBI، با بیش از 40 میلیارد دلار تقلب بیمه ای تنها در ایالات متحده، جای تعجب نیست که بیمه گران به دنبال راه هایی برای کاهش پرداخت های جعلی هستند. یک راه حل استفاده از یادگیری ماشینی برای ایجاد مدل هایی است که می توانند احتمال قانونی بودن یا نبودن یک ادعا را پیش بینی کنند.
مدل سازی ادعای متقلبانه یک مثال عالی از این است که چگونه می توان از مدل سازی پیش بینی برای تجزیه و تحلیل تقلب در صنعت بیمه استفاده کرد. برای مثال، با استفاده از مدلی که بر اساس پرداختهای گذشته ساخته شده است، یک بیمهگر میتواند یک سیستم امتیازدهی را برای ادعاها اعمال کند و به طور خودکار آنهایی را که احتمال کلاهبرداری بالایی دارند رد یا پرچمگذاری کند.
همانطور که تحقیقات نشان میدهد، ادعاهای تقلبی نه تنها سود بیمهگران را کاهش میدهند، بلکه میتوانند مستقیماً به ورشکستگی شرکت منجر شوند. علاوه بر این، کلاهبرداری به مصرفکنندگانی که سالانه 700 دلار در قالب افزایش حق بیمه پرداخت میکنند، آسیب میزند.
روشهای سنتی تشخیص تقلب ناکارآمد و ناکارآمد هستند، زیرا تجزیه و تحلیل دستی مقادیر زیادی از دادهها در مقیاس برای انسان غیرممکن است، که به تقلب اجازه میدهد از شکافها عبور کند.
پتانسیل آکیو در این زمینه فراتر از صنعت بیمه است. کلاهبرداری مدلسازی یک مورد استفاده محبوب در بخش مالی نیز هست، به عنوان مثال برای کمک به حذف برنامهها و تراکنشهای کارت اعتباری تقلبی.
پذیرش کردن بیمه عمر برای مشتریان ضعیف
بسیاری از شرکت های بیمه عمر، مشتریانی را که از برخی بیماری های جدی مانند سرطان رنج می برند، متقبل نمی شوند. این به این دلیل است که آنها را ملزم می کند که یک فرآیند ارزیابی پزشکی طولانی و پرهزینه را برای مشتری صرف کنند.
بسیاری از شرکت های بیمه عمر، مشتریانی را که از برخی بیماری های جدی مانند سرطان رنج می برند، تعهد نمی کنند. این به این دلیل است که آنها را ملزم می کند که یک فرآیند ارزیابی پزشکی طولانی و پرهزینه را برای مشتری صرف کنند.
در بیمه، اصطلاح “مستضعف” به متقاضیانی اطلاق می شود که معیارهای استاندارد را برای به دست آوردن نرخ بسیار مقرون به صرفه ندارند. در نتیجه، متقاضیان آسیب دیده اغلب بیمه نشده یا کمتر بیمه شده اند.
این یک تصمیم تجاری عاقلانه برای افزایش پوشش برای مشتریان آسیب دیده است و هوش مصنوعی Akkio می تواند این قابلیت را ارائه دهد.
در حالی که بسیاری از افرادی که از یک بیماری جدی رنج می برند را می توان به طور دقیق از طریق یک پرسشنامه شناسایی کرد، Akkio می تواند با ادغام تاریخچه پزشکی و شرایط متقاضی به درجه بالاتری از دقت دست یابد. مدلهای پیشبینی مبتنی بر هوش مصنوعی از این عوامل برای پیشبینی خطر پذیرهنویسی یک بازمانده از بیماری جدی استفاده میکنند. این مدل خطر مرگ را که نقص نهایی بیمه است، پیش بینی می کند.
برای بیمهگران، ساخت مدل در عرض چند دقیقه امکانپذیر است، خط جدیدی از کسبوکار باز میشود و سود نهایی را افزایش میدهد.
فین تک و بانکداری
تراکنش های متقلبانه با کارت اعتباری
کلاهبرداری کارت اعتباری یک مشکل بزرگ است که میلیاردها دلار در سال هزینه دارد. تراکنش های تقلبی در سال 2018 28 میلیارد دلار هزینه داشت و به سرعت در حال رشد هستند. در واقع، انتظار می رود تا پایان دهه زیان سالانه از 40 میلیارد دلار فراتر رود.
با یادگیری ماشینی بدون کد Akkio، احتمال تراکنش های تقلبی را می توان بدون زحمت پیش بینی کرد. این امر باعث کاهش تعداد معاملات تقلبی و در عین حال افزایش رضایت مشتری می شود. برای بانک ها، این به معنای هزینه کمتر برای هر تراکنش و درآمد و سود بیشتر است.
کشف کلاهبرداری توسط Akkio برای تراکنش های کارت اعتباری نمونه ای از نحوه کمک Akkio به بانک ها است. با استفاده از مجموعه دادههای تراکنش تاریخی، مدلهای یادگیری ماشین الگوهای مشکوک را شناسایی میکنند و عواملی را که اغلب در تراکنشهای کارت اعتباری نادیده گرفته میشوند، مانند تغییرات آدرس IP، رفتار پرخطر مرور، یا سطح پایین تعامل با تراکنش، در نظر میگیرند.
با استفاده از روشهای آموزشی اختصاصی هوش مصنوعی، Akkio میتواند برای ساخت مدلهای تراکنش متقلبانه در عرض چند دقیقه استفاده شود که میتوانند در هر تنظیماتی از طریق API مستقر شوند.
نرخ های پیش فرض اعتباری
نرخ نکول اعتبار درصدی از وام هایی است که نکول می کنند. مدلسازی مشکل نرخ پیشفرض اعتبار به دلیل پیچیدگی آن دشوار است، زیرا عوامل زیادی بر احتمال نکول یک فرد یا شرکت تأثیر میگذارند، مانند صنعت، امتیاز اعتبار، درآمد و زمان.
درک عواملی که منجر به نکول کارت اعتباری می شود می تواند به وام دهندگان کمک کند تا ریسک وام دادن به وام گیرندگان را بهتر ارزیابی کنند و در نهایت به افزایش سود کمک کنند. ریسک اعتباری معیاری برای سنجش احتمال ناتوانی فرد در بازپرداخت بدهی است، و این همان چیزی است که وام دهندگان برای تعیین اینکه آیا اعتبار ارائه می دهند یا خیر، استفاده می کنند. در امور مالی، ریسک اعتباری، ریسک نکول تعهدی است که به دلیل نامشخص بودن جریان نقدی آتی ایجاد می شود.
API آکیو میتواند به هر سازمانی که نیاز به مدلهای ریسک اعتباری دقیق دارد، در کسری از زمانی که برای ساخت آنها نیاز دارد، کمک کند. Akkio ساخت مدلی را آسان می کند که احتمال پیش فرض را بر اساس داده های گذشته پیش بینی می کند.
علاوه بر این، Akkio می تواند برای بازآموزی خودکار مدل استفاده شود، به طوری که پس از ساخت یک مدل، نگهداری و به روز رسانی آن در صورت نیاز آسان باشد. این امکان را برای سازمانها فراهم میکند که نه تنها در زمان انجام وظایف مدلسازی پیشبینیکننده صرفهجویی کنند، بلکه همیشه به مدلهای خود اطمینان داشته باشند.
مدیریت ثروت دیجیتال
مدیریت ثروت دیجیتال یک زمینه رقابتی است. در این بازار، فقط داشتن بهترین محصولات سرمایه گذاری نیست، بلکه نحوه توزیع موثر آنها در حین مدیریت دارایی های مشتری نیز مطرح است. الگوریتمهای یادگیری ماشین Akkio را میتوان برای تجزیه و تحلیل دائمی دادههای پورتفولیوی مشتریان فعلی شما برای یافتن فرصتهای جدید و تعیین ارزشها برای هر یک از مشتریان بالقوه استفاده کرد.
مهم است که سبد خود را متنوع کنید تا مطمئن شوید که در فناوری ها و شرکت های مناسب سرمایه گذاری می کنید. هوش مصنوعی میتواند با یافتن فرصتهای سرمایهگذاری جدید به پرتفویهای متنوع کمک کند
Akkio به مدیران دارایی کمک میکند تا بر اساس سرمایهگذاریهای قبلی و اطلاعات جمعیتی و همچنین اطلاعاتی مانند ریسکپذیریشان، یاد بگیرند که کدام مشتریان بیشتر در دستههای خاص سرمایهگذاری میکنند.
هوش مصنوعی حتی می تواند برای خودکارسازی تجزیه و تحلیل سرمایه گذاری، با دریافت داده های مالی از منابعی مانند بازار اوراق بهادار برای پیش بینی احتمال افزایش یا کاهش قیمت سهام استفاده شود. سپس این پیشبینیها میتوانند توصیههای استراتژی در زمان واقعی را برای افراد یا سرمایهگذاران نهادی ارائه دهند.
نتیجه؟ یک استراتژی مدیریت دارایی موفق که مشتریان جدید را جذب می کند و همزمان سهم بیشتری از دارایی های مشتری موجود را به خود اختصاص می دهد.
علاوه بر این، الگوریتمها برای دههها در معاملات سهام مورد استفاده قرار گرفتهاند. به عنوان مثال، مقاله ای در نیویورک تایمز در سال 1986 با عنوان «ماشین فردا وال استریت» استفاده از رایانه برای ارزیابی فرصت های تجاری جدید را مورد بحث قرار داد.
تجارت هوش مصنوعی امروزی شکلی از معاملات خودکار است که از الگوریتمهایی برای یافتن الگوها در بازار و انجام معاملات استفاده میکند. معامله گران هوش مصنوعی همچنین می توانند برای بهینه سازی پرتفوی ها با توجه به اهداف ریسک و بازده استفاده شوند و اغلب در سازمان های تجاری استفاده می شوند.
سیستمهای معاملاتی مبتنی بر هوش مصنوعی همچنین میتوانند از تحلیل احساسات برای شناسایی فرصتهای معاملاتی در بازار اوراق بهادار استفاده کنند. الگوریتم های پیشرفته هوش مصنوعی می توانند سیگنال های خرید و فروش را بر اساس لحن پست های رسانه های اجتماعی پیدا کنند.
Blockchain
Blockchain یک پایگاه داده غیرمتمرکز است که اطلاعات را در بلوک های داده ذخیره می کند. بلوک ها از طریق رمزنگاری به یکدیگر متصل می شوند تا تاریخچه ای از تمام تراکنش ها ایجاد شود. این سیستم بر اجماع بین کاربران شبکه در مورد اعتبار اطلاعات و داده ها متکی است و بلاک چین ها را نسبت به سایر انواع پایگاه های داده ایمن تر می کند.
با این حال، با محبوبیت بیشتر فناوری Blockchain، تهدیدات امنیتی نیز در حال افزایش است. حمله به بلاک چین های بزرگتر مانند بیت کوین و اتریوم به دلیل منابع بسیار زیاد، عملا غیرممکن است. گفته می شود که صدها Blockchainکوچکتر در معرض خطر هستند.
MIT Technology Review گزارش میدهد، «شعارها و سرفصلهای بازاریابی که فناوری را «غیرقابل هک» مینامیدند، کاملاً اشتباه بودند، زیرا اگر مهاجم بتواند بیش از 51 درصد از قدرت محاسباتی دفاع از شبکه را جمعآوری کند که به مهاجم اجازه میدهد مالکیت خود را مجدداً تخصیص دهد، بلاک چینها را میتوان بازنویسی کرد. از وجوه یکی از این نمونهها زمانی است که اتریوم کلاسیک (یک انشعاب از اتریوم) 3 بار در یک ماه مورد حمله 51 درصدی قرار گرفت. در سال 2020، بیش از 120 حمله بلاک چین رخ داد که منجر به زیان نزدیک به 4 میلیارد دلار شد.
در حالی که جلوگیری از حملات 51 درصدی به مشارکت کنندگان توزیع شده بستگی دارد که منابع محاسباتی را به دفاع زنجیره ای تخصیص می دهند، کاربران و صرافی ها باید بتوانند رفتار غیرعادی را هنگامی که روی یک زنجیره اتفاق می افتد تشخیص دهند (بنابراین آنها می توانند تلاش کنند تا از دست دادن سرمایه را به حداقل برسانند).
الگوریتمهای یادگیری ماشین Akkio میتوانند ناهنجاریها را در زمان واقعی شناسایی کنند، به شما هشدار میدهند و شما را قادر میسازند تا قبل از وارد شدن آسیبهای اضافی سریع اقدام کنید. با AutoML Akkio، ساختن یک سیستم تشخیص تقلب متناسب با نیازهای شما فقط چند دقیقه طول می کشد.
مراقبت های بهداشتی
بهینه سازی تحویل دارو
زنجیره تامین دارویی بهطور مشهوری شکننده است که منجر به کمبود، هزینههای بالاتر و مسائل ایمنی میشود. بخشی از این مسائل مربوط به سیستم های بهینه سازی نشده دارورسانی است.
شرکت های داروسازی میلیون ها دلار را برای حمل نمونه های دارو به پزشکان و بیمارستان ها هزینه می کنند. تحلیلهای ساده موقعیتهایی را برای ادغام سفارشها آشکار میکنند، مانند زمانی که یک مکان دو یا چند نمونه دارو درخواست میکند. با این حال، نگاه دستی به دادهها برای تلفیق سفارش به سرعت در مقیاس غیرممکن میشود.
هوش مصنوعی با پیشبینی اینکه کدام سفارشها را میتوان ادغام کرد، مهم نیست که چقدر پیچیده یا تعداد سفارشهایی که باید پردازش شوند، به بهینهسازی فرآیندهای تحویل زنجیره تامین کمک میکند. این مزیت قاتل هوش مصنوعی است: در مقایسه با تکنیک های سنتی فوق العاده سریع و دقیق است.
از هوش مصنوعی می توان برای یافتن بهترین مکان ها برای حمل و نقل تلفیقی، تخمین صرفه جویی در هزینه و بهبود رضایت مشتری استفاده کرد. به جای خاموش کردن آتشسوزیهای مرتبط با زنجیرههای تامین بهینهنشده، سیستمهای سلامت اکنون میتوانند بر آنچه واقعاً مهم است تمرکز کنند: کمک به بیماران.
گرایش به سمت بیماری
در دنیایی از داده های تقریبا نامحدود و تجزیه و تحلیل های قدرتمند، به راحتی می توان فهمید که چرا سیستم های بهداشتی به دنبال راه هایی برای درک بهتر سلامت بیماران خود هستند. با پلتفرمهای هوش مصنوعی، تیمها میتوانند به منابع دادههای مختلف مانند نتایج آزمایشگاهی و HIE متصل شوند و از مدلهای یادگیری ماشینی برای پیشبینی شدت وضعیت بیمار و نوع مراقبتی که نیاز دارند استفاده کنند.
متخصصان پزشکی باید غربالگری بیمارانی را که ممکن است احتمال بیشتری برای یک بیماری خاص داشته باشند، در نظر بگیرند. اگر بیمارانی را ببینند که ممکن است مستعد ابتلا به بیماری باشد، درمان فوری او به نتایج سلامتی بهتری منجر میشود، علاوه بر این که مسئولیت مالی بیشتری نسبت به ندیدن او تا زمانی که آن را حمل میکنند، خواهد داشت.
در نهایت، استفاده از هوش مصنوعی برای خودکارسازی مدلسازی گرایش به بیماری، این پتانسیل را دارد که سالانه میلیونها دلار در بیمارستانها و سایر ارائهدهندگان مراقبتهای بهداشتی صرفهجویی کند، زیرا بازدیدهای غیرضروری از اورژانس و پذیرش مجدد را کاهش میدهد.
مدل سازی اشغال ICU
تامین نیروی انسانی و بودجه برای ICU بیمارستان همیشه یک تصمیم دشوار است، و زمانی که نمی دانید بار بیمار چقدر سریع تغییر می کند، حتی سخت تر می شود. با یادگیری ماشینی، بیمارستانها میتوانند به راحتی با مدلسازی دادههای تاریخی برای محاسبه روندها، پیشبینیهایی درباره اشغال خود انجام دهند.
بیش از حد ظرفیت، همانطور که اخیراً در اتاق های ICU در سراسر جهان اتفاق افتاده است، اغلب مستقیماً منجر به مرگ بیمار می شود. نرخ اشغال بالاتر به وضوح با نرخ مرگ و میر بالاتر مرتبط است.
با هوش مصنوعی، بیمارستانها میتوانند به سرعت مدلی ایجاد کنند که نرخ اشغال را پیشبینی کند، که در نتیجه منجر به تصمیمگیری دقیقتر بودجه و کارکنان میشود. مدلهای یادگیری ماشینی به بیمارستانها کمک میکنند تا جان افراد را نجات دهند، ناکارآمدی کارکنان را کاهش دهند و برای بیماران ورودی بهتر آماده شوند.
مدلهای پیشبینی همچنین به بیمارستانها کمک میکند تا در مورد خدماتی که باید به بیماران خود ارائه دهند، تصمیمگیری بهتری بگیرند. مراقبت های بهداشتی در چند سال گذشته به سرعت در حال تغییر بوده است، با تمرکز بیشتر بر ارائه مراقبت های جامع و برنامه های درمانی فردی. علاوه بر این، پیشبینی میتواند به بیمارستانها در پیشبینی نیازهای بیمار و ارائه خدمات مناسب برای برآورده کردن انتظارات کمک کند.
در نهایت، الگوریتمهای یادگیری ماشین، پیشبینی گام بعدی در عملیات خود را برای بیمارستانها آسان میکنند و تصمیمات آگاهانهتری در مورد نیازهای کارکنان آینده اتخاذ میکنند. نتیجه، بیماران سالم تر، شادتر و نتیجه قوی تر برای بیمارستان ها است.
تخمین خطر سپسیس
سپسیس یک وضعیت تهدید کننده زندگی است که می تواند به طور ناگهانی و با عواقب مخرب ایجاد شود. این یکی از علل اصلی مرگ در بخشهای مراقبتهای ویژه و در بیمارستانها است و بروز سپسیس در حال افزایش است. پزشکان و پرستاران دائماً به دلیل نیاز به ارزیابی سریع خطر ابتلا به سپسیس در بیماران به چالش کشیده می شوند، که در صورت غیر اختصاصی بودن علائم می تواند دشوار باشد.
چندین دهه پیش، سپسیس چندان نگران کننده نبود. امروزه، سپسیس تقریباً یک پنجم مرگ و میر انسان را تشکیل می دهد.
هوش مصنوعی با ارائه بینش های مبتنی بر داده برای شناسایی بیمارانی که در معرض خطر ابتلا به سپسیس هستند، تخصص متخصصان پزشکی را تکمیل می کند. متخصصان پزشکی می توانند از قدرت یادگیری ماشینی برای جمع آوری داده های بیمار و ایجاد هشدارهای خودکار متناسب با نیازهای منحصر به فرد هر بیمار استفاده کنند.
مدلهای یادگیری ماشینی برای یادگیری از دادههای تاریخی، که میتواند شامل موارد سپسیس گذشته باشد، طراحی شدهاند تا پیشبینیهای دقیقی ارائه دهند، و متخصصان مراقبتهای بهداشتی را قادر میسازند تا با اطمینان بیمارانی را که در معرض خطر بالای ابتلا به سپسیس هستند شناسایی کنند.
خطر بستری مجدد در بیمارستان
میانگین هزینه پذیرش مجدد در بیمارستان از 15000 تا 25000 دلار متغیر است که منجر به هدر رفتن منابع، آزمایشات غیرضروری، درمانهای بالقوه مضر، تأخیر در مراقبت از بیمار و سایر پیامدهای مخرب میشود.
یادگیری ماشینی میتواند به کاهش خطر بستری مجدد از طریق مدلهای تحلیلی پیشبینیکننده که بیماران در معرض خطر را شناسایی میکنند، کمک کند. با استفاده از داده های تاریخی ترخیص از بیمارستان، اطلاعات جمعیتی، کدهای تشخیصی و سایر عوامل، متخصصان پزشکی می توانند احتمال بستری مجدد بیمار را محاسبه کنند.
هوش مصنوعی تشخیص اینکه کدام بیماران بیشتر در معرض خطر بستری مجدد هستند را برای بیمارستان ها آسان می کند. ابزارهای هوش مصنوعی بدون کد به هیچ کار فناوری اطلاعات یا کدنویسی نیاز ندارند، بنابراین بیمارستان ها می توانند در هزینه ها صرفه جویی کنند و کیفیت مراقبتی را که ارائه می دهند بهبود بخشند.
در نهایت، مورد خطر بستری مجدد در بیمارستان هوش مصنوعی می تواند به بیمارستان ها کمک کند تا هزینه های خود را کاهش دهند و کیفیت مراقبتی را که می توانند به بیماران خود ارائه دهند افزایش دهند.
بخش عمومی
مبارزه با تروریسم
تروریسم یکی از نگرانی های اصلی سازمان های اطلاعاتی و مجری قانون در سراسر جهان است. پس از 11 سپتامبر، جلوگیری از حملات تروریستی به یک دستورالعمل اصلی برای تعدادی از سازمانهای دولتی تبدیل شد.
همانطور که در گزارش دفتر مبارزه با تروریسم سازمان ملل در مورد هوش مصنوعی توضیح داده شده است، سازمان های دولتی می توانند از مدل سازی پیش بینی برای شناسایی پرچم های قرمز افراط گرایی، شناسایی گسترش اطلاعات نادرست تروریستی و مقابله با روایت های تروریستی استفاده کنند.
یادگیری ماشینی فقط برای بازاریابی نیست. همچنین میتوان از آن برای کمک به جلوگیری از حملات تروریستی با شناسایی الگوهای رویدادهای گذشته و پیشبینی رویدادهای آینده، نجات جانها و تبدیل جهان به مکانی امنتر استفاده کرد.
تشخیص تقلب
تقلب موضوعی است که نه تنها برای دولت و شهروندانش بلکه برای شرکت ها نیز هزینه بر است. هر سازمان دولتی از IRS گرفته تا سازمان تامین اجتماعی متحمل زیان های قابل توجهی از کلاهبرداری می شود.
در واقع، همانطور که در گزارش انجمن بازرسان خبره تقلب مورد بررسی قرار گرفته است، مطالعه ای روی نزدیک به 3000 مورد کلاهبرداری شغلی نشان داد که نهادهای دولتی “بیشترین بخش در میان پرونده های تقلب مورد تجزیه و تحلیل قرار گرفتند.” در حالی که بسیاری از گفتمان های عمومی پیرامون دولت ها به عنوان عاملان تقلب متمرکز است، واقعیت اغلب این است که کارمندان و سازمان های دولتی اغلب هدف طیف گسترده ای از فعالیت های کلاهبرداری هستند.
شناسایی فعالیتهای متقلبانه ممکن است دشوار باشد و برای آژانسها زمان و منابع ارزشمندی را به همراه داشته باشد. در نهایت، هوش مصنوعی تشخیص فعالیتهای تقلبی را در زمان وقوع برای سازمانهای دولتی آسان میکند و در زمان و منابع آنها صرفهجویی میکند و در عین حال از دلارهای مالیات دهندگان نیز محافظت میکند.
تهدید داخلی
در عصر تحول دیجیتال، بردارهای حمله روز به روز بزرگتر می شوند. در نتیجه، حتی سازمانهای دولتی نیز در معرض نفوذ افراد داخلی (یا کارمندان سابق) هستند که میخواهند از دادههای خود برای اهداف مخرب استفاده کنند.
در عین حال، تعدادی از تهدیدات داخلی وجود دارد که می توانند ماهیت بی ضرر به نظر برسند، اما با این وجود پرهزینه به نظر می رسند، مانند ارسال اطلاعات شرکت از طریق یک حساب شخصی، یا حتی پیکربندی نادرست اعتبار دسترسی.
به عنوان مثال، در حالی که شرکتهای امنیت سایبری دوست دارند تکنیکهای دقیق خود را خصوصی نگه دارند، تحقیقات نشان میدهد که هوش مصنوعی میتواند ایمیلهای مخرب را به دقت شناسایی کند، ایمیلهایی که در صورت عدم شناسایی میلیاردها دلار هزینه برای دولتها دارد.
برای اطمینان از اینکه شرکت ها مجبور نیستند برای این نوع نقض های داخلی هزینه ای بپردازند، آژانس ها باید به طور فعال هرگونه سوء استفاده احتمالی را با استفاده از یادگیری ماشینی برای شناسایی خطرات مسدود کنند.
امنیت سایبری
حملات سایبری در حال افزایش است و عواقب واقعی برای مردم عادی به همراه دارد. به عنوان مثال، اخیراً هکرها خطوط لوله بنزین و سوخت جت را متوقف کردند و تولید گوشت گاو و خوک را در یک تامین کننده پیشرو در ایالات متحده متوقف کردند. اینها تنها چند نمونه از ده ها هزار حمله سالانه امنیت سایبری هستند.
یکی از چالش های اصلی در امنیت سایبری امروزه، یک حمله رو به رشد است. هر چه بیشتر و بیشتر دنیای ما دیجیتالی می شود، داده های بیشتری برای پیگیری وجود دارد و هکرها راحت تر می توانند مورد توجه قرار نگیرند. بررسی دستی این دادهها فقط میتواند شما را به این نتیجه برساند، اما هوش مصنوعی میتواند حجم عظیمی از دادهها را در زمان واقعی اسکن کند.
هوش مصنوعی بدون کد، تیمهای امنیتی را قادر میسازد تا مدلهایی را بسازند، مستقر کرده و بهروزرسانی کنند تا تهدیدات دریافتی را در زمان واقعی پیشبینی کنند، خواه اسکن ایمیلهای دریافتی برای تهدیدات مخرب یا پرچمگذاری مربوط به فعالیت IP باشد، بنابراین میتوانند از نقض قبل از وقوع آن جلوگیری کنند.
در نهایت، این تیمهای امنیتی را قادر میسازد تا در معرض خطر قرار گرفتن خود را کاهش دهند و برای یک چشمانداز سایبری خصمانه فزاینده آماده شوند. تیم هایی که نتوانند هوش مصنوعی را برای امنیت سایبری مستقر کنند، در مقایسه با سایر بازیگران بازار که این کار را انجام می دهند، در برابر حملات آسیب پذیرتر خواهند بود.
پشتیبانی مشتری
دسته بندی موضوع اتیکت پشتیبانی
خدمات خوب به مشتریان از اهمیت جهانی برخوردار است، نظرسنجیها نشان میدهد که 96 درصد مشتریان احساس میکنند خدمات مشتری در انتخاب وفاداری آنها به یک برند مهم است.
خدمات مشتری نیز عامل اصلی حفظ مشتری است. به عبارت دیگر، اگر افراد از خدماتی که دریافت میکنند راضی باشند، احتمال بیشتری برای ماندن در یک شرکت دارند.
طبقهبندی بلیطهای پشتیبانی مشتری مبتنی بر هوش مصنوعی میتواند به شرکتها کمک کند تا به پرسشها به شیوهای کارآمد پاسخ دهند. با ترکیب پردازش زبان طبیعی و یادگیری ماشینی، میتوان از هوش مصنوعی برای گروهبندی خودکار پرسشها در دستههای از پیش تعریفشده استفاده کرد و تیمهای پشتیبانی مشتری انتخاب بخش مناسب را برای رسیدگی به یک پرس و جو بر اساس حوزه تخصص خود آسان میکند.
اساساً، با هضم سؤالات گذشته برای یافتن الگوها از نظر محتوا، هوش مصنوعی میتواند نحوه طبقهبندی بلیطهای جدید را با دقت و کارآمدی بیشتر بیاموزد. این بدان معنی است که با گذشت زمان، طبقه بندی بلیط مبتنی بر هوش مصنوعی به بخشی جدایی ناپذیر از استراتژی خدمات مشتری هر سازمان تبدیل خواهد شد.
اولویت بندی اتیکت پشتیبانی
تیمهای پشتیبانی مشتری باید تعداد زیادی از درخواستهای مشتری را در مدت زمان محدود رسیدگی کنند و اغلب مطمئن نیستند که کدام بلیطها باید ابتدا بررسی شوند. مدلهای یادگیری ماشینی میتوانند بلیطها را بر اساس فوریتشان رتبهبندی کنند، و ابتدا به فوریترین بلیطها پرداخته میشود. این کار تیم ها را از بار تصمیم گیری در مورد بلیط هایی که به بیشترین توجه نیاز دارند، رها می کند و زمان بیشتری را برای رسیدگی واقعی به بلیط ها و جلب رضایت مشتریان آزاد می کند.
تجزیه و تحلیل پیشبینیکننده همچنین برای شناسایی الگوها در دادهها مفید است، به طوری که پرسشهای مشتری میتوانند با دقت بیشتری با پاسخها پاسخ داده شوند، و به تیمها اجازه میدهد تا با پاسخدهی سریعتر، تجربه مشتری خود را بهبود بخشند.
تحلیل احساسات رسانه های اجتماعی
رسانههای اجتماعی ابزاری ارزشمند برای تیمهای بازاریابی و پشتیبانی مشتری هستند، اما چشماندازی پیچیده و سریع در حال حرکت هستند. هر روز میلیون ها نفر افکار، نظرات و پیشنهادات خود را در مورد برندهایی که با آنها در تعامل هستند در رسانه های اجتماعی ارسال می کنند. از یک نظر تند و تیز گرفته تا یک بررسی تند، پست های رسانه های اجتماعی می توانند تاثیر زیادی بر موفقیت شرکت شما داشته باشند.
یادگیری ماشینی میتواند به تیمها کمک کند تا حجم عظیمی از دادههای رسانههای اجتماعی را با طبقهبندی خودکار احساسات پستها در زمان واقعی به لطف مدلهای آموزشدیده بر روی دادههای تاریخی، درک کنند. این به تیم ها امکان می دهد سریع تر و موثرتر به بازخورد مشتریان پاسخ دهند.
در نهایت، این به بازاریابان و تیم های خدمات مشتری اجازه می دهد تا علائم هشدار دهنده اولیه نارضایتی را قبل از اینکه از کنترل خارج شوند و بیهوده مشتریان را دور کنند، شناسایی کنند.
یافتن سوابق تکراری مشتری در پایگاه داده شما
در فرآیند ورود داده ها، می دانیم که خطاهایی رخ خواهد داد. انسانها کامل نیستند و این شامل کسانی میشود که دادهها را کدگذاری میکنند: اشتباهات ویرایشی ممکن است رخ دهد مانند معکوس کردن یک “S” یا “Z” در سند ورودی. منطقی است که فرض کنیم ممکن است چندین نسخه از رکوردهای شما وجود داشته باشد که در آن افراد مختلف ممکن است یک حرف را اشتباه تایپ کرده باشند یا متوجه قالب بندی متناقض مانند «اسمیث» در مقابل «اسمیت» نشده باشند، قبل از اینکه آن را به عنوان نسخه جدید ذخیره کنید.
بهعلاوه، دادهها را میتوان توسط سیستمهای متعدد، با مقادیر ستونهای مختلف وارد کرد، به طوری که موارد تکراری با روشهای سنتی یافت نمیشوند (مثلاً یک سیستم دارای نام و نام خانوادگی است، در حالی که سیستم دیگری ایمیل خود را دارد).
تشخیص موارد تکراری بسیار دشوار است و نیاز به مداخله دستی برای شناسایی سوابق تکراری دارد. این می تواند زمان بر و مستعد خطای انسانی باشد. هوش مصنوعی متفاوت است: کاملاً خودکار است و می تواند موارد تکراری را برای همه انواع فیلدها با دقت بالا شناسایی کند.
هوش مصنوعی برای کارهای پیچیده deduplication ضروری است، زیرا یک رکورد می تواند چندین بار در پایگاه داده شما نمایش داده شود. با هوش مصنوعی، میتوانید این موارد تکراری را حتی اگر دارای فیلدهای داده متفاوتی باشند، شناسایی کنید – پاکسازی پایگاه دادهتان را آسان میکند تا بدون مداخله دستی به بهترین شیوهها پایبند باشد.
امتیازدهی سرنخ
امتیازدهی سرنخ یک راه قدرتمند برای تعیین اینکه کدام سرنخ ها بیشتر به توجه شما نیاز دارند است. هوش مصنوعی تیمها را قادر میسازد تا بهطور خودکار احتمال تبدیل شدن هر سرنخ به مشتری پرداختکننده را پیشبینی کنند. با داشتن این بینش، تیمهای بازاریابی میتوانند تصمیم بگیرند که کدام یک را دنبال کنند و زمان صرف کنند، و کدام یک را پشت سر بگذارند.
امتیازدهی سرنخ امروزی توسط یادگیری ماشینی انجام میشود که از دادههای تاریخی، چه از Salesforce، Snowflake، Google Sheets یا هر منبع دیگری استفاده میکند تا احتمال تبدیل شدن یک سرنخ معین را پیشبینی کند.
این بینش به تیمهای بازاریابی کمک میکند تا سرنخهایی را که نیاز به توجه بیشتری دارند و همچنین آنهایی که احتمالاً برای تیم اتلاف وقت هستند را شناسایی کنند.
پیش بینی فروش
به عنوان یک تجارت، پیش بینی یکی از مهمترین وظایف شماست. این چیزی است که به شما امکان می دهد از قبل برنامه ریزی کنید و از بودجه خود بهتر استفاده کنید.
یادگیری ماشینی می تواند به شما کمک کند این کار را با دقت بی نظیری انجام دهید، حتی در محیط های اقتصادی غیرقابل پیش بینی. هوش مصنوعی بدون کد می تواند برای ساخت سریع مدلی از داده های فروش گذشته و پیش بینی فروش احتمالی در آینده استفاده شود. با هوش مصنوعی بدون کد، میتوانید با آپلود کاتالوگ محصولات و دادههای فروش گذشته، در عرض چند ثانیه پیشبینیهای دقیقی دریافت کنید.
به جای تکیه بر قوانین سرانگشتی یا احساسات درونی، هوش مصنوعی یک رویکرد علمی تری ارائه می دهد که به شما امکان می دهد در مورد بودجه، استخدام کارکنان و کمپین های تبلیغاتی تصمیمات بهتری بگیرید.
این برای مشاغلی ضروری است که باید بدانند چگونه برای آینده بودجه بندی کنند یا منابع محدود خود را بهینه کنند. مدلهای پیشبینی را میتوان از طریق یک رابط مبتنی بر وب، API، Salesforce یا حتی از طریق Zapier استقرار داد و شروع به کار را در هر محیطی بدون نیاز به دانش علم داده آسان میکند.
بازاریابی
بازاریابی مستقیم
نحوه مصرف ما تغییر کرده است. در گذشته، ما به فروشگاه می رفتیم، آنچه را که نیاز داشتیم انتخاب می کردیم و آن را می خریدیم. امروزه میتوانیم آنچه را که نیاز داریم از خانه خود سفارش دهیم و درب منزل تحویل بگیریم.
در نتیجه، روش بازاریابی ما تغییر کرده است. بازاریابی مستقیم راهی عالی برای کسب و کارها برای دستیابی به مشتریان بالقوه خود است و این فرصتی است که تا حد زیادی کمتر از آن استفاده شده است.
با این حال، تعیین اینکه کدام مشتریان احتمال بیشتری برای خرید دارند، اغلب دشوار است. بازاریابی برای سرنخهای بیعلاقه صرفاً اتلاف وقت و پول نیست – میتواند یک تغییر بزرگ برای آن سرنخها از تصمیمگیری برای خرید باشد.
اینجاست که هوش مصنوعی مبتنی بر داده وارد می شود.
هوش مصنوعی می تواند بهترین افراد بالقوه را در میان یک گروه خاص پیدا کند و بهترین راه برای دستیابی به آنها را تعیین کند. این بدان معناست که شما می توانید به سرعت و به آسانی با ارزش ترین سرنخ ها را شناسایی کنید و سپس با پیام شخصی که نیازهای خاص آنها را بیان می کند با آنها تماس بگیرید.
با هوش مصنوعی بدون کد، میتوانید بدون هیچ زحمتی سرنخها را بر اساس احتمال تبدیلشان اولویتبندی و طبقهبندی کنید، همه اینها با کسری از زمان و هزینهای که روشهای سنتی نیاز دارند.
استفاده از برنامه وفاداری
برنامه وفاداری یک برنامه پاداش است که به مشتریانی که از یک مؤسسه خاص خرید می کنند امتیاز یا جوایز دیگری می دهد. یک مثال معمولی ممکن است برنامهای باشد که به ازای هر دلاری که در فروشگاه خرج میشود، ده امتیاز برای هر مشتری فراهم میکند و اگر مشتری ۱۰۰۰ امتیاز جمعآوری کند، ۱۰ دلار از خریدش به او تخفیف داده میشود.
برنامههای وفاداری برای تشویق مشتریان به خرید منظم از شرکت طراحی شدهاند و معمولاً بسته به میزان هزینهای که مشتری در هر بار هزینه میکند، از سطوح مختلف پاداش تشکیل شدهاند. مؤثرترین نوع برنامه وفاداری، برنامه ای است که بر اساس میزان پول خرج شده، مزایای بیشتری را ارائه می دهد، زیرا مشتریان بیشتر با چشم انداز افزایش پاداش انگیزه می گیرند.
متأسفانه، حتی اگر درک خوبی از رفتارها و ترجیحات مشتریان خود داشته باشید، نمی توان پیش بینی کرد که کدام پاداش به طور مؤثرتری به آنها انگیزه می دهد. در حالی که کافی شاپ محله شما ممکن است برای هر پنجمین بازدید یک قهوه رایگان ارائه دهد، مقیاس و پیچیدگی برنامههای وفاداری برای شرکتهای بزرگ و مبتنی بر دادهها بسیار بیشتر است.
الگوریتمهای یادگیری ماشینی میتوانند دادههای گذشته را تجزیه و تحلیل کنند و تشخیص دهند که کدام بخشهای مشتری احتمالاً به پاداشهای خاص پاسخ مثبت میدهند. این به مدیران کمک می کند تا تصمیمات آگاهانه ای در مورد اینکه کدام پاداش و چه زمانی ارائه دهند، اتخاذ کنند و احتمال تبدیل شدن آنها را افزایش می دهد.
بهترین پیشنهاد بعدی
یکی از بهترین راه هایی که بازاریابان می توانند تجربه ای شخصی سازی شده برای مشتریان ایجاد کنند، در نظر گرفتن «بهترین پیشنهاد بعدی» است. این امر مستلزم آن است که بازاریابان تمام اقدامات ممکنی را که می توانند با آن مشتری انجام دهند را در نظر بگیرند و سپس مناسب ترین آنها را انتخاب کنند.
به عنوان مثال، فرض کنید که یک مشتری برای کسب اطلاعات در مورد اجاره از یک وب سایت بازدید می کند. مشتری نمی تواند بین یک استودیو یا یک آپارتمان یک خوابه تصمیم بگیرد، بنابراین او برای اطلاعات بیشتر در مورد هر دو جستجو می کند و نمی تواند اطلاعات قطعی پیدا کند. در این مورد، «بهترین پیشنهاد بعدی» میتواند ایجاد یک ایمیل شخصیشده با پیوندهایی به مقالات و ویدیوها از هر دو نوع آپارتمان باشد، بنابراین مشتری میتواند تصمیم بگیرد که کدام یک برای او بهتر است.
انجام این کار به صورت دستی به وضوح در مقیاس غیرممکن است. کسب و کارها می توانند از هوش مصنوعی برای ارائه محصول مناسب به فرد مناسب در زمان مناسب استفاده کنند.
کسبوکارها میتوانند بهطور خودکار در زمان واقعی، با استفاده از مدلهای پیشبینیکننده که اولویتهای مشتری، حساسیت قیمت، و در دسترس بودن محصول را در نظر میگیرند، یا هر دادهای که برای آموزش ارائه میشود، توصیههایی ارائه دهند.
پیشبینی پیشنهاد مناسب برای فرد مناسب در زمان مناسب، کار بزرگی است، اما هوش مصنوعی بهینهسازی عملیات خود را برای خردهفروشان آسان میکند. بهتر از همه، خرده فروشان برای استقرار مدل های پیش بینی به هیچ دانشمند داده یا متخصص هوش مصنوعی نیاز ندارند – هوش مصنوعی بدون کد به طور خودکار توصیه ها را بدون نیاز به کدنویسی تقویت می کند.
اسناد بازاریابی چند کانالی
اگر بودجه بازاریابی شما شامل تبلیغات در رسانههای اجتماعی، وب، تلویزیون و موارد دیگر باشد، تشخیص اینکه کدام کانالها بیشترین مسئولیت را در فروش دارند میتواند دشوار باشد. با مدلسازی اسناد مبتنی بر یادگیری ماشین، تیمها میتوانند به سرعت و به آسانی شناسایی کنند که کدام فعالیتهای بازاریابی بیشترین درآمد را دارند.
مدل های اسناد بازاریابی به طور سنتی از طریق تجزیه و تحلیل آماری در مقیاس بزرگ ساخته می شوند که زمان بر و گران است. پلتفرمهای هوش مصنوعی بدون کد میتوانند مدلهای انتساب دقیق را در عرض چند ثانیه بسازند و تیمهای غیر فنی میتوانند مدلها را در هر شرایطی مستقر کنند.
این به تیمهای بازاریابی اجازه میدهد تا هزینهها را پایین نگه دارند و در عین حال دقیقا مشخص کنند که بودجه بازاریابی خود را کجا اختصاص دهند تا بهترین بازگشت سرمایه را بهینه کنند. در نهایت، این اطمینان را آسان تر می کند که هر دلاری که برای بازاریابی خرج می شود ارزش آن را دارد، بنابراین شما به طور مداوم بیشترین بهره را از بودجه بازاریابی خود می برید.
با خودکار کردن اسناد، بازاریابان می توانند بر چیزهای خسته کننده غلبه کنند و در مورد آنچه واقعاً مهم است خلاقیت بیشتری داشته باشند. با داشتن دانش در مورد نحوه عملکرد کانالهای خاص، بازاریابان میتوانند در نهایت کانالهای با عملکرد بالا را کاهش دهند، عقب ماندگیها را از بین ببرند و راهبردی برای حرکت رو به جلو تعیین کنند.
شخصی سازی محصول
امروزه مشتریان انتظار محصولات و محتوای شخصی سازی شده را دارند.
یادگیری ماشینی به کسبوکارها این امکان را میدهد تا در نهایت با پیام مناسب، در زمان مناسب و در کانال مناسب، مشتریان را هدف قرار دهند.
به عنوان مثال، به جای استفاده از یک پیام برای دسترسی به همه افراد در وب سایت خود، یادگیری ماشینی می تواند برای تجزیه و تحلیل احساسات نظرات مشتریان در سایت شما یا ابزارهای CRM یا رسانه های اجتماعی شما برای ارائه بخش های مختلف مشتریان با پیام های مختلف استفاده شود.
علاوه بر این، پلتفرمهای هوش مصنوعی را میتوان بر روی دادههای خرید محصول تاریخی برای ساخت یک مدل توصیههای محصول آموزش داد. به عنوان مثال، اگر یک مشتری محصول خاصی را در گذشته خریداری کرده باشد، یک API AI می تواند برای توصیه محصولات مرتبطی که احتمالاً مشتری به آن علاقه مند است، استفاده کند.
این می تواند یک پیشرانه قدرتمند برای نتیجه نهایی باشد، زیرا تحقیقات نشان می دهد که 80٪ از مصرف کنندگان زمانی که برندها تجربیات شخصی ارائه می دهند، تمایل بیشتری به خرید دارند.
فراتر از تجربیات شخصی سازی شده، هوش مصنوعی حتی می تواند برای شخصی سازی محصولات و خدمات خود استفاده شود.
در حالی که امروزه، بسیاری از این محصولات شخصیشده توسط یک طراح یا سفارش سفارشی ایجاد میشوند، هوش مصنوعی شخصیسازیشده این فرآیند را بسیار کارآمدتر میکند و محصول را با نیازهای یک مشتری منطبق میکند و آن را در عرض چند روز تحویل میدهد.
ریزش مشتری
نرخ ریزش، همچنین به عنوان نرخ فرسایش شناخته می شود، تعداد مشتریانی است که اشتراک خود را در یک بازه زمانی معین قطع می کنند. برای رشد یک شرکت، باید مشتریان جدید بیشتری نسبت به نرخ ریزش خود به دست آورد.
نرخ ریزش، همچنین به عنوان نرخ فرسایش شناخته می شود، تعداد مشتریانی است که اشتراک خود را در یک بازه زمانی معین قطع می کنند. برای رشد یک شرکت، باید مشتریان جدید بیشتری نسبت به نرخ ریزش خود به دست آورد.
جلوگیری از ریزش مشتری بسیار چالش برانگیز است، به همین دلیل برای شرکت ها بسیار مهم است که فعال باشند.
خوشبختانه هوش مصنوعی قدرت انجام این کار را دارد. الگوریتمهای یادگیری ماشینی میتوانند الگوهای دادهای رایج در میان مشتریانی را که احتمالاً از بین میروند، شناسایی کنند، مانند آنهایی که هزینههای بالایی برای خرید دارند یا آنهایی که با شخصیت مشتری ایدهآل شما همسو نیستند.
با داشتن این دانش، میتوانید استراتژی حفظ خود را با هدف قرار دادن مشتریان پرخطر با پیشنهادات یا مشوقهای شخصیسازی شده قبل از خروج، بهینه کنید. علاوه بر این، تیمهای بازاریابی میتوانند استراتژیهای خود را برای جلوگیری از سرنخهای پرمخاطب تنظیم کنند.
هر چه داده های شما بیشتر باشد، بهتر است. پلتفرم های هوش مصنوعی مانند Akkio به شما این امکان را می دهند که با منابع داده خود در هر کجا که هستند – سیستم CRM، انبارهای داده و سایر پایگاه های داده – کار کنید تا بهترین مدل را برای پیش بینی ریزش کسب و کار خود ایجاد کنید.
بهترین حرکت بعدی
وقتی نوبت به بازاریابی میرسد، همیشه تاکتیکهای بیشتری نسبت به زمان یا منابع برای کشف وجود دارد. تلاش برای تصمیم گیری برای اینکه روی کدام کانال یا فعالیت تمرکز کنید که بیشترین تأثیر را بر درآمد داشته باشد به این معنی است که مجبور به حدس زدن هستید.
هوش مصنوعی می تواند این حدس ها را آزمایش کند. الگوریتمهای یادگیری ماشینی میتوانند با دادههای همه کانالهای بازاریابی شما و همچنین اطلاعات چرخه عمر مشتری تغذیه شوند تا مشخص شود کدام فعالیتها به احتمال زیاد هر مشتری را به خرید نزدیکتر میکند.
تست A/B یک راه عالی برای تعیین بهترین روش تخصیص منابع بازاریابی است، اما تنها در صورتی که بتوانید موفقیت را به طور دقیق اندازه گیری کنید. اینجاست که یادگیری ماشین برتر است: نه تنها میتواند فروش را اندازهگیری و پیشبینی کند، بلکه میتواند پیشبینی کند که در صورت امتحان هر تاکتیک بازاریابی چه اتفاقی میافتد.
مناقصه گوگل ادوردز
گوگل ادوردز بخش بزرگی از اکثر بودجه های تبلیغاتی را تشکیل می دهد، اما دریافت پیشنهاد درست ممکن است دشوار باشد. اگر خیلی کم پیشنهاد دهید، فرصت ها را از دست می دهید. اگر بیش از حد بالا پیشنهاد دهید، بازگشت سرمایه بازاریابی شما کاهش می یابد.
با این حال، یادگیری ماشینی میتواند با ایجاد مدلی از فعالیتهای بازاریابی و فروش گذشته برای پیشبینی حجم فروش قابل انتساب به هر AdWord، این فرآیند را آسانتر کند، و تعیین قیمت بهینه پیشنهاد برای دستیابی به بازده بازگشت سرمایه (ROI) هدف را آسانتر میکند و در عین حال از گم شدن کلمه جلوگیری میکند. به یک رقیب
ساخت مدل های حراجی که بتواند رفتار پیچیده انسانی را به تصویر بکشد برای تیم ها بسیار دشوار و زمان بر است. اما از هوش مصنوعی بدون کد می توان برای ساخت مدل های دقیق تنها با چند کلیک استفاده کرد. شرکت ها می توانند این مدل ها را به راحتی با یک API در هر تنظیماتی یا حتی با ابزارهای بدون کد مانند Zapier به کار گیرند.
در نهایت، این به تیمهای بازاریابی امکان میدهد اثربخشی هزینههای تبلیغاتی خود را افزایش دهند، که برای موفقیت در یک چشمانداز رقابتی بیشتر برای توجه مصرفکننده ضروری است. تیم هایی که نتوانند هوش مصنوعی را برای مناقصه AdWords مستقر کنند، مستقیماً به رقبای خود که از استراتژی های داده محور استفاده می کنند، ضرر خواهند کرد.
امتیازدهی سرب
امتیازدهی سرنخ بخش مهمی از هر کمپین بازاریابی است زیرا به شما کمک می کند زمان و منابع خود را بر روی مشتریان بالقوه ای متمرکز کنید که به احتمال زیاد به مشتریان پولی تبدیل می شوند. به عبارت دیگر، یک مدل امتیازدهی دقیق سرب به شما کمک می کند تا جایی که پول است بروید. در واقع، بیش از دو سوم از بازاریابان به امتیازدهی پیشرو به عنوان یکی از مهمترین مشارکتکنندگان درآمد اشاره میکنند.
با این حال، امتیازدهی دقیق سرب میتواند دشوار باشد. سنجش میزان تعامل مشتری با محصول شما بدون دانستن چیزهای زیادی در مورد آنها آسان نیست، بنابراین مدلهای سنتی امتیازدهی سرنخ برای تعیین امتیاز به علاقه مشتری متکی هستند. رویکردهای سنتی بسیار محدود هستند، زیرا لزوماً توانایی مشتری یا احتمال واقعی خرید را نشان نمی دهند.
اینجاست که هوش مصنوعی وارد میشود. مدلهای یادگیری ماشینی از طیف گستردهای از عوامل برای کسب امتیاز بازاریابی استفاده میکنند. با مدلهای امتیازدهی سرنخ مبتنی بر داده، میتوانید به تصمیمهای بازاریابی خود اطمینان بیشتری داشته باشید، زیرا به نقاط دادهای بیشتر از علاقه مشتری بالقوه نگاه میکنید.
حفظ کارکنان
مطالعات نشان داده است که جذب و حفظ استعدادهای برتر یکی از مهمترین عوامل موفقیت یک شرکت است. به هر حال، میانگین خروج کارکنان یک سوم کامل حقوق سالانه آنها هزینه دارد.
با این حال، همانطور که روابط کارمند و کارفرما در حال تغییر است، چالش جذب و حفظ استعدادهای برتر سخت تر می شود. سال به سال، فرسایش کارکنان در حال افزایش است و برخی این بحران را “استعفای بزرگ” می نامند.
اما امیدی وجود دارد: داده ها. پلتفرمهای هوش مصنوعی بدون کد به متخصصان منابع انسانی این امکان را میدهند که حجم عظیمی از دادهها را اسکن کنند – از استخدام خطوط لوله گرفته تا سابقه کارمندان یا بررسی عملکرد – تا بینشهایی را کشف کنند تا بهترین افراد شما برای تیم شما کار کنند.
با هوش مصنوعی بدون کد، میتوانید از الگوریتمهای یادگیری ماشینی برای ایجاد مدلهای پیشبینی استفاده کنید که به شما امکان میدهد پیشبینی کنید که چه زمانی یک کارمند ممکن است در حال بررسی تغییر شغل باشد، چه زمانی ممکن است در فکر ترک موقعیت فعلی خود باشد، یا اگر به سادگی ناراضی است.
این رویکرد مبتنی بر داده، مسائل بالقوه را قبل از تبدیل شدن به مشکلات بزرگ روشن میکند و به تیمهای منابع انسانی بینشهای باکیفیتی را میدهد که برای تصمیمگیری آگاهانهتر نیاز دارند. با ابزارهایی مانند Zapier، تیمهای منابع انسانی حتی میتوانند مدلهای پیشبینیکننده را در هر محیطی بدون نوشتن کد اجرا کنند.
چگونه می توانم یک مدل یادگیری ماشین ایجاد و اجرا کنم؟
برای بسیاری، یادگیری ماشین ممکن است جادو باشد. اما حقیقت این است، همانطور که دیدیم، این آمار واقعاً پیشرفتهای است که با رشد دادهها و رایانههای قدرتمندتر تقویت شده است.
با این حال، مدلهای یادگیری ماشین ابزارهای همه کاره فوقالعادهای هستند که میتوانند ارزش فوقالعادهای را در بین واحدهای تجاری بیافزایند. قبلاً دیدیم، برای مثال، تیمهای مالی چگونه میتوانند از یادگیری ماشینی برای پیشبینی تقلب استفاده کنند، تیمهای بازاریابی میتوانند سرنخها را کسب کنند یا ریزش را پیشبینی کنند، تیمهای منابع انسانی میتوانند فرسایش را پیشبینی کنند، و موارد دیگر.
ساختن مدلهای یادگیری ماشینی برای امکانپذیر ساختن این موارد استفاده، زمانی یک کار سخت و پرمشقت بود که به متخصصان فنی برای مهندسی دادهها، ساخت خطوط لوله، کدگذاری، نگهداری زیرساختها و موارد دیگر نیاز داشت.
همانطور که بررسی کردیم، هوش مصنوعی بدون کد به هر کسی اجازه می دهد تا بدون نیاز به مهارت های برنامه نویسی، مدل های یادگیری ماشینی را به تنهایی ایجاد و استقرار دهد. با این حال، برای اینکه واقعاً مبتنی بر هوش مصنوعی شوید، این که هوش مصنوعی برای شما کار کند یک ارتقاء یکباره نیست. این سفری است که به درک مدیریت داده و استفاده از یادگیری ماشین نیاز دارد.
یکی دیگر از دلایل مشکلساز بودن هوش مصنوعی مبتنی بر کد این است که کمبود برنامهنویس وجود دارد و انتظار میرود با رشد صنعت هوش مصنوعی، این کمبود افزایش یابد. همانطور که ACM گزارش میدهد، علیرغم افزایش تقاضا برای فارغالتحصیلان علوم کامپیوتر، که ناشی از تاخیر در پردازش ویزای دانشجویی، دسترسی محدود به وامهای آموزشی و تحریمهای سفر است، واقعاً اخیراً کاهش یافته است.
با داده ها شروع کنید
همانطور که دیدیم، داده ها سوختی است که موتورهای یادگیری ماشین را نیرو می دهد، به همین دلیل است که آماده سازی داده ها هنگام ساخت یک مدل بسیار مهم است.
عبارت «هر چه بیشتر بهتر» در یادگیری ماشین صادق است، که معمولاً با مجموعه دادههای بزرگتر و با کیفیت بالا عملکرد بهتری دارد. با Akkio، میتوانید این دادهها را از منابع متعددی مانند یک فایل CSV، یک برگه اکسل، یا از Snowflake (یک انبار داده) یا Salesforce (یک مدیر ارتباط با مشتری) متصل کنید.
برای مثال، فرض کنید میخواهید از هوش مصنوعی برای کسب امتیاز فروش استفاده کنید. اگر کسبوکار شما از Salesforce استفاده میکند، میتوانید مستقیماً مجموعه دادههای فروش خود را به هم متصل کنید و سپس ستونی را انتخاب کنید که به بسته شدن یا نشدن معامله مربوط میشود.
بسیاری از تیمهای فروش کوچکتر، با استفاده از Google Sheets یا Excel برای سازماندهی دادههای سرنخ، کار را ساده میکنند. هر دوی این منابع را میتوان به راحتی به Akkio نیز متصل کرد، و مدل را به همان روش میسازید – با انتخاب ستونی که میخواهید پیشبینی کنید.
در طرف دیگر طیف، برخی از شرکتهای بزرگتر از Snowflake برای مدیریت حجم عظیمی از دادههای فروش استفاده میکنند که میتواند به راحتی با Akkio نیز ادغام شود.
یک مدل را آموزش دهید
ما بررسی کردهایم که چگونه مدلهای یادگیری ماشین الگوریتمهای ریاضی هستند که برای یافتن الگوها در دادهها استفاده میشوند. برای آموزش یک مدل یادگیری ماشینی، به مجموعه داده با کیفیتی نیاز دارید که معرف مشکلی باشد که میخواهید حل کنید. بیایید یک مثال عملی را مرور کنیم.
در Akkio، میتوانید با زدن «افزودن مرحله» پس از اتصال مجموعه داده و سپس «پیشبینی» یک مدل را آموزش دهید. سپس، به سادگی ستونی را برای پیش بینی انتخاب کنید.
به طور کلی، دو نوع مدل وجود دارد که می توانید آموزش دهید: مدل های طبقه بندی و مدل های رگرسیون.
چند نمونه از طبقهبندی شامل پیشبینی تقلب، پیشبینی تبدیل سرنخ و پیشبینی ریزش است. مقادیر خروجی این مثالها همه «بله» یا «خیر» یا کلاسهای مشابه هستند.
از سوی دیگر، مدلهای رگرسیون برای پیشبینی طیفی از متغیرهای خروجی، مانند درآمد یا هزینههای فروش، استفاده میشوند.
پس از انتخاب «پیشبینی»، آموزش هر یک از مدلها یکسان است: نام ستونی را که میخواهید پیشبینی کنید، خواه تبدیل، ریزش، فرسایش، تقلب یا هر معیار دیگری نامیده شود، انتخاب میکنید. شما همچنین می توانید یک “حالت تمرین” را انتخاب کنید، که از 10 ثانیه زمان تمرین تا 5 دقیقه متغیر است، که در آن زمان های طولانی تر تمرین ممکن است به مدل های دقیق تر منجر شود.
پشت صحنه
در حالی که فرآیند آموزش تنها با چند کلیک انجام می شود، کارهای زیادی در پس زمینه انجام می شود.
این کار با مهندسی نرم افزار شروع می شود تا زمینه را برای خود پلتفرم فراهم کند. مهندسی نرم افزار شاخه ای از مهندسی است که به طراحی، توسعه، بهره برداری و نگهداری نرم افزار می پردازد. اکثر فعالیت های توسعه نرم افزار امروزی توسط تیمی از مهندسان انجام می شود.
اما این همه چیز نیست. DevOps برای کمک به تولید برنامه های کاربردی هوش مصنوعی استفاده می شود.
DevOps یک روش توسعه نرم افزار است که بر همکاری بین توسعه دهندگان نرم افزار و سایر متخصصان فناوری اطلاعات تمرکز دارد. هدف آن کوتاه کردن زمان بین ایده نرم افزار و پذیرش آن توسط کاربران نهایی است.
برای ساختن خود مدل های تشخیص الگوی هوش مصنوعی، تعدادی از رویکردهای مختلف استفاده می شود. تشخیص الگو توانایی شناسایی یک الگو در داده ها و تطبیق آن الگو در داده های جدید است. این بخش کلیدی یادگیری ماشین است و می تواند تحت نظارت یا بدون نظارت باشد.
رویکرد بیزی به هوش مصنوعی یک رویکرد احتمالی برای تصمیم گیری است. روش های بیزی برای تخمین احتمال یک فرضیه بر اساس دانش قبلی و شواهد جدید استفاده می شود.
تکنیک دیگر کاهش ابعاد است، فرآیندی که با شناسایی موارد مهم و حذف ابعاد غیر مهم، تعداد ابعاد یک مجموعه داده را کاهش می دهد.
K-means clustering و PCA یا Principle Component Analysis دو روشی هستند که معمولاً با هم استفاده می شوند. برای گروه بندی نقاط داده مرتبط، k-means پارتیشن را در داده ها پیدا می کند، در حالی که PCA بردار عضویت خوشه را پیدا می کند.
جنگل تصادفی یکی دیگر از روش های رایج است. جنگل تصادفی یک روش یادگیری ماشینی است که چندین درخت تصمیم را بر روی ویژگی های ورودی یکسان تولید می کند. سلسله مراتب درختان تصمیم با انتخاب تصادفی مشاهدات برای ریشه یابی هر درخت ساخته می شود.
شیب نزول یک تکنیک متداول در روش های مختلف آموزش مدل است. برای یافتن مینیمم محلی در یک تابع از طریق فرآیند تکرار شونده “نزولی گرادیان” خطا استفاده می شود.
این روشهای هوش مصنوعی اغلب با ابزارهایی مانند TensorFlow، ONNX و PyTorch ساخته میشوند.
TensorFlow یک کتابخانه نرمافزار منبع باز برای هوش ماشینی است که مجموعهای از ابزارها را برای دانشمندان داده و مهندسان یادگیری ماشین برای ساخت و آموزش شبکههای عصبی فراهم میکند. این یکی از محبوب ترین چارچوب های یادگیری عمیق است.
ONNX یک زبان مدلسازی منبع باز برای شبکههای عصبی است که به منظور تسهیل انتقال الگوریتمهای خود بین سیستمها و برنامهها برای توسعهدهندگان هوش مصنوعی ایجاد شده است. این چارچوب AI منبع باز ساخته شده است تا به طور گسترده برای هر کسی که می خواهد از آن استفاده کند در دسترس باشد.
PyTorch یک کتابخانه یادگیری ماشین منبع باز برای Python است که بر اساس Torch است. PyTorch شتاب GPU را فراهم می کند و می تواند به عنوان یک ابزار خط فرمان یا از طریق نوت بوک های Jupyter استفاده شود. PyTorch با رویکرد Python-first طراحی شده است و به محققان اجازه می دهد تا مدل ها را به سرعت نمونه سازی کنند.
همه این فرآیندهای آموزش مدل تکراری هستند و بسیاری از ملاحظات آموزش مدل فنی در نظر گرفته شده است.
یکی از این نگرانیها تطبیق بیش از حد است، که زمانی اتفاق میافتد که یک مدل سعی میکند هر ورودی فردی را که ممکن است دریافت کند، به جای اینکه بتواند الگوهای خاصی را در دادهها پیشبینی کند، پیشبینی کند.
بهترین شیوه هایی وجود دارد که می توان هنگام آموزش مدل های یادگیری ماشینی به منظور جلوگیری از وقوع این اشتباهات دنبال کرد. یکی از این بهترین شیوهها منظمسازی است که با کوچک کردن پارامترها (مانند وزنهها) تا زمانی که تأثیر کمتری بر پیشبینیها داشته باشند، به بیش از حد برازش کمک میکند. بهترین روش دیگر برای آموزش موفق، استفاده از اعتبارسنجی متقابل است.
نگرانی دیگر «نفرین ابعاد» نام دارد. این زمانی اتفاق میافتد که تعداد ورودیهای یک مدل برای عملکرد صحیح آن خیلی زیاد شود، بهویژه اگر بسیاری از ورودیها از نظر آماری با نتیجه پیشبینیشده مرتبط نباشند. راهی برای دور زدن این موضوع، سادهسازی یا کاهش تعداد ویژگیها یا ابعاد مورد استفاده به منظور پیشبینی دقیقتر است – این به عنوان «کاهش ابعاد» شناخته میشود.
یکی از تکنیکهای کاهش ابعاد، آنالیز مؤلفه اصلی یا PCA نامیده میشود. PCA حجم زیادی از داده ها را به چند دسته تبدیل می کند که برای توصیف ویژگی های آنچه که اندازه گیری می کنید مفید هستند.
ارزیابی عملکرد مدل
همه مدلهای یادگیری ماشینی برابر نیستند. یک ضرب المثل رایج در دنیای هوش مصنوعی وجود دارد: “آشغال داخل، زباله بیرون.” اگر از دادههای با کیفیت پایین برای ساخت یک مدل یادگیری ماشینی استفاده شود، این مدل پیشبینیهای با کیفیت پایین را نیز تولید میکند.
تعدادی معیار وجود دارد که می توانید برای ارزیابی عملکرد یک مدل از آنها استفاده کنید. پس از ساخت هر مدلی در Akkio، یک گزارش مدل، از جمله بخش «کیفیت پیشبینی» دریافت میکنید.
طبقه بندی
اگر یک مدل طبقهبندی ساختهاید، معیارهای کیفیت شامل درصد دقت، دقت، یادآوری و امتیاز F1 و همچنین تعداد مقادیر پیشبینیشده درست و نادرست برای هر کلاس است.
در اینجا معنی این فیلدها آمده است:
دقت: دقت میزان دفعات صحیح بودن یک پیش بینی را اندازه می گیرد و با تقسیم تعداد پیش بینی های صحیح بر تعداد کل پیش بینی ها محاسبه می شود.
دقت: دقت کسری از مثبت های واقعی از مثبت های پیش بینی شده است. این برای در نظر گرفتن زمانی مفید است که هزینه مثبت کاذب زیاد است، مانند تشخیص هرزنامه ایمیل. اگر یک ایمیل مهم به اشتباه به عنوان هرزنامه طبقه بندی شود، اطلاعات مهم را از دست خواهید داد.
یادآوری: یادآوری تعداد موارد مثبت واقعی مدل شما است. این برای در نظر گرفتن زمانی مفید است که هزینه منفی کاذب بالا باشد، مانند پیشبینی سرطان بدخیم.
امتیاز F1: امتیاز F1 دقت و یادآوری را در یک متریک ترکیب می کند و آنها را وزن می کند تا بین در نظر گرفتن مثبت کاذب و منفی کاذب تعادل برقرار کند.
پیش بینی
از آنجایی که پیشبینی برای پیشبینی محدودهای از مقادیر استفاده میشود، برخلاف مجموعه محدودی از کلاسها، معیارهای ارزیابی متفاوتی وجود دارد که باید در نظر گرفته شود.
پس از ساخت یک مدل پیشبینی، مانند مدلسازی هزینه، مقدار RMSE و فیلدی به نام «معمولاً درون» را مشاهده خواهید کرد.
RMSE مخفف Root Mean Square Error است که انحراف استاندارد باقیمانده ها (خطاهای پیش بینی) است. فیلد “معمولا درون” مقادیری را ارائه می دهد که درک آنها در زمینه ساده تر است، مانند مدل هزینه ای که “معمولاً در محدوده” 40 دلار از ارزش واقعی است.
با استفاده از یک مدل، پیش بینی کنید
VentureBeat گزارش میدهد که 87 درصد از مدلهای یادگیری ماشین هرگز به تولید نمیرسند. این موضوع توسط یک مطالعه جداگانه تأیید شده است که نشان میدهد فقط 14.6 درصد از شرکتها از قابلیتهای هوش مصنوعی در تولید استفاده کردهاند.
ما نمی توانیم آنها را سرزنش کنیم. هوش مصنوعی کار دشواری است و بسیاری از شرکتها سعی میکنند با ساخت خطوط لوله داده، زیرساختهای مدل و موارد دیگر چرخ را دوباره اختراع کنند. در همان زمان، نظرسنجی McKinsey نشان داد که فقط 8٪ از پاسخدهندگان درگیر روشهای مقیاسبندی مؤثر هستند. این بدان معناست که بسیاری از شرکت ها در حال ساخت مدل هستند، اما قادر به استقرار آنها نیستند، به ویژه در مقیاس.
با Akkio، کسبوکارها میتوانند بدون زحمت مدلها را در مقیاسی در طیف وسیعی از محیطها مستقر کنند. کاربران فنی بیشتر میتوانند از API ما برای ارائه پیشبینیها در عمل در هر تنظیماتی استفاده کنند، در حالی که کاربران تجاری میتوانند پیشبینیها را مستقیماً در Salesforce، Snowflake، Google Sheets و هزاران برنامه دیگر با قدرت Zapier اجرا کنند.
اصطلاح API مخفف “Application Programming Interface” است و راهی برای نرم افزار برای صحبت با نرم افزارهای دیگر است. API ها اغلب در رایانش ابری و برنامه های کاربردی اینترنت اشیا برای اتصال سیستم ها، خدمات و دستگاه ها استفاده می شوند.
با پرس و جو از نقاط پایانی API Akkio، کسب و کارها می توانند داده ها را به هر مدلی ارسال کنند و پیش بینی را در قالب یک ساختار داده JSON دریافت کنند.
برای زمینه، ساختار داده به نحوه سازماندهی داده ها در یک برنامه کامپیوتری اشاره دارد. ساختار داده ها بر اساس دو مفهوم ساخته شده اند: انواع داده ها و دستکاری داده ها. انواع داده ها نوع داده ها را در ساختار تعریف می کنند، مانند عدد، کلمه یا تصویر. دستکاری داده ها نحوه سازماندهی داده ها در ساختار را مشخص می کند، مانند خطی، سلسله مراتبی یا درختی.
مدلها حتی میتوانند از طریق برنامه وب مستقر شوند تا فوراً یک URL برای اشتراکگذاری با دیگران دریافت کنند. هنگامی که برای یک برنامه وب روی “Deploy” کلیک می کنید، یک iFrame embed (فریم درون خطی) نیز دریافت خواهید کرد که یک تگ HTML است که می تواند در هر سایتی جاسازی شود.
کاربرانی که مدلها را به کار میگیرند میتوانند از فضای ذخیرهسازی ابری استفاده کنند که مقیاس بارگذاری نامحدود داده را در خود جای دهد. هوش مصنوعی موتور رشد بعدی برای ذخیره سازی ابری است، با نرخ رشد سالانه عظیم.
علاوه بر این، این سرورهای ابری خانه خوشههای عظیم واحد پردازش گرافیکی (GPU) هستند. الگوریتمهای هوش مصنوعی که به محاسبات ریاضی زیادی مانند شبکههای عصبی نیاز دارند، برای پردازش GPU مناسب هستند، به طوری که سرورهای ابری مقیاسپذیری نامحدود پیشبینیهای مدل را امکانپذیر میکنند.
یادگیری مستمر (چیست و چرا اهمیت دارد)
اهمیت یادگیری مستمر در یادگیری ماشینی را نمی توان اغراق کرد. یادگیری مستمر فرآیند بهبود عملکرد سیستم با به روز رسانی سیستم با در دسترس قرار گرفتن داده های جدید است. یادگیری مستمر کلید ایجاد مدل های یادگیری ماشینی است که سال ها بعد مورد استفاده قرار می گیرند.
فرآیند بهروزرسانی یک سیستم با دادههای جدید یا «یادگیری» چیزی است که همیشه توسط افراد انجام میشود. یادگیری مداوم به دنبال تکرار این فرآیند در یک ماشین است. نکته کلیدی برای ساختن مدلهای قوی که همچنان در آینده ارزشمند باشند، یادگیری از اطلاعات جدید به محض در دسترس شدن است. این به ماشین اجازه میدهد تا رفتار خود را در هنگام پاسخ دادن به اطلاعات جدید، درست مانند انسانها، تنظیم کند.
هر چه یک ماشین اطلاعات بیشتری داشته باشد، در پاسخگویی به اطلاعات جدید موثرتر خواهد بود. میزان استفاده از یادگیری مستمر به تعیین میزان هوشمندی سیستم و میزان پاسخگویی آن به موقعیتهای جدید کمک میکند.
عملیات ML
عملیات یادگیری ماشین (MLOps) خلاصه ای از خدمات و ابزارهایی است که یک سازمان برای کمک به آموزش و استقرار مدل های یادگیری ماشین استفاده می کند.
خدمات MLOps به کسبوکارها و توسعهدهندگان کمک میکند تا با هوش مصنوعی شروع کنند، با ارائه خدماتی که شامل آمادهسازی داده، آموزش مدل، تنظیم فراپارامتر، استقرار مدل، و نظارت و نگهداری مداوم است. سازمانهایی که خط لوله آموزشی بزرگی دارند، به MLO برای مقیاس کارآمد آموزش و عملیات تولید نیاز دارند.
این خدمات به توسعه دهندگان این امکان را می دهد تا از قدرت هوش مصنوعی بهره ببرند بدون اینکه نیازی به سرمایه گذاری در زیرساخت ها و تخصص لازم برای ساخت سیستم های هوش مصنوعی داشته باشند.
با Akkio، عملیات یادگیری ماشین در پسزمینه استاندارد، ساده و خودکار میشود و به کاربران غیر فنی اجازه میدهد تا به همان کالیبر ویژگیهای کارشناسان صنعت دسترسی داشته باشند.
آماده سازی داده ها
برای جمعبندی، آمادهسازی داده، فرآیند تبدیل دادههای خام به قالبی است که برای مدلسازی مناسب است، که آن را به یکی از اجزای کلیدی عملیات یادگیری ماشین تبدیل میکند. این فرآیند معمولاً شامل تقسیم داده ها به بخش هایی برای آموزش و اعتبار سنجی و عادی سازی داده ها است.
این به معنای تقسیم تصادفی داده ها به مجموعه ای از دو زیر مجموعه است که به عنوان “داده های آموزشی” و “داده های آزمایشی” شناخته می شود (به این نمونه گیری طبقه ای گفته می شود). سپس اولین زیرمجموعه برای تلاش برای یافتن الگوها در دادهها آموزش داده میشود، اما مدل نمیداند که چه چیزی در آینده میآید. زیرمجموعه دوم به عنوان ورودی جدیدی استفاده می شود که هوش مصنوعی قبلاً ندیده است، که به پیش بینی بهتر نتایج کمک می کند.
به این ترتیب، وقتی با استفاده از این مدل، پیشبینیهایی را روی ورودیهای جدید ایجاد میکنید، دقیقتر هستند، زیرا از نمونههایی استفاده میکنید که قبلاً توسط مدل دیده نشدهاند.
آماده سازی داده ها همچنین می تواند شامل مقادیر عادی سازی در یک ستون باشد به طوری که هر مقدار بین 0 و 1 قرار می گیرد یا به محدوده خاصی از مقادیر تعلق دارد (فرآیندی که به عنوان binning شناخته می شود).
برای مثال، اگر شخصی اطلاعات جمعیت شناختی در مورد افرادی که از وب سایت آنها بازدید می کنند و می توانند کالاها را به صورت آنلاین خریداری کنند ارائه می دهد، تقسیم آنها به مرد یا زن مفید خواهد بود. زیر 18 یا بالای 18 سال؛ و غیره، به منظور طبقه بندی رفتار آنها در هنگام مرور بر اساس این گروه بندی ها.
آموزش مدل
مرحله آموزش جایی است که مدلهای یادگیری ماشین از الگوریتمها تولید میشوند. الگوریتم ممکن است تعیین کند که کدام ویژگی از داده ها برای نتیجه مطلوب پیش بینی می کنند. این مرحله را می توان به چند مرحله فرعی از جمله انتخاب ویژگی، آموزش مدل و بهینه سازی هایپرپارامتر تقسیم کرد.
هدف از انتخاب ویژگی یافتن زیرمجموعهای از ویژگیها است که همچنان تنوع در دادهها را نشان میدهد، در حالی که ویژگیهایی را که نامربوط هستند یا همبستگی ضعیفی با نتیجه مورد نظر دارند، حذف میکند.
الگوریتم های یادگیری ماشینی توسط آمار استنباطی برای “آموزش” مدل پشتیبانی می شوند، به طوری که می تواند در مورد داده های جدید “استنتاج” کند.
یادگیری ماشینی اغلب از طریق یک حلقه بازخورد عمل می کند که به موجب آن داده های ورودی با یک الگوریتم خالی شروع می شود، که سپس الگوهایی را در آن داده ها در طی چندین تکرار پیدا می کند. این اطلاعات به الگوریتم بازگردانده میشود که پارامترهای آن را اصلاح میکند و تا زمانی که مدل بهینه پیدا شود، از تکرار دیگری برای اصلاح میگذرد.
در نهایت، بهینه سازی هایپرپارامتر تعیین می کند که چه مجموعه ای از تنظیمات هایپرپارامتر باید بر اساس برخی معیارها مانند هزینه یا کارایی محاسباتی استفاده شود. عواملی که هنگام ارزیابی تنظیم هایپرپارامتر مدل باید در نظر گرفته شود می تواند شامل موارد زیر باشد:
دقت در مقابل سرعت
درجه استحکام در برابر بیش از حد برازش و عدم تناسب به دلیل تعداد زیادی پارامتر قابل تنظیم در مقابل مبادله دقت
استقرار مدل
فرآیند استقرار یک مدل هوش مصنوعی اغلب دشوارترین مرحله MLO ها است، که توضیح می دهد که چرا بسیاری از مدل های هوش مصنوعی ساخته شده اند، اما مستقر نشده اند.
چندین ملاحظات مختلف برای برنامه ریزی وجود دارد، از جمله: چگونه داده ها پرس و جو می شوند؟ مدل هوش مصنوعی در چه محصول یا خدماتی تعبیه خواهد شد؟ چگونه اطمینان حاصل کنیم که تمام قطعات مدل در طول زمان همانطور که انتظار می رود با هم کار کنند؟
اینها تنها بخشی از بسیاری از سؤالاتی است که باید قبل از استقرار به آنها پرداخته شود. با Akkio، تیم ها می توانند مدل ها را بدون نگرانی در مورد این ملاحظات مستقر کنند و می توانند محیط استقرار خود را با کلیک انتخاب کنند.
امروزه روش های خلاقانه زیادی برای به کارگیری هوش مصنوعی وجود دارد. به عنوان مثال، میتوانید مدلها را روی تلفنهای همراه با پهنای باند محدود یا حتی سرورهای هوش مصنوعی آفلاین مستقر کنید. هوش مصنوعی آفلاین یک گزینه استقرار مدل است که می تواند برای ارائه پیش بینی ها به صورت محلی یا “در لبه” برای موارد استفاده مانند دوربین های مدار بسته هوشمند که ممکن است در منطقه مرده بی سیم قرار داشته باشند یا حتی برنامه های تشخیصی پزشکی مجهز به هوش مصنوعی که با داده های بهداشتی حساس
جمع بندی
ساخت و به کارگیری هر نوع مدل هوش مصنوعی می تواند دلهره آور به نظر برسد، اما با ابزارهای هوش مصنوعی بدون کد مانند Akkio، واقعاً بدون دردسر است.
تا زمانی که تیمها دادههایی را در اختیار داشته باشند که میتواند از ابزارهایی مانند Salesforce، Snowflake یا حتی فقط یک فایل Google Sheets استفاده کنند، میتوانند بدون زحمت مدلهای هوشمند را برای همه چیز، از پیشبینی ریزش تا بهینهسازی فروش، آموزش داده و به کار گیرند.





